Приведение матрицы к треугольному виду
Ниже два калькулятора для приведения матриц к треугольному, или ступенчатому, виду. Первый использует для этого метод Гаусса, второй — метод Барейса. Описание методов и немного теории — под калькуляторами.
Приведение матрицы к треугольному виду (метод Гаусса)
3 2 3 4 4 4 3 2 1 4 4 3 2 3 1 1Точность вычисленияЗнаков после запятой: 4
Треугольная матрица (метод Гаусса)
Треугольная матрица (метод Гаусса с выбором максимума в столбце)
Треугольная матрица (метод Гаусса с выбором максимума по всей матрице)
content_copy Ссылка save Сохранить extension Виджет
Приведение матрицы к треугольному виду (метод Барейса)
3 2 3 4 4 4 3 2 1 4 4 3 2 3 1 1Точность вычисленияЗнаков после запятой: 4
Треугольная матрица (метод Барейса)
Треугольная матрица (метод Барейса с выбором максимума в столбце)
Треугольная матрица (метод Барейса с выбором максимума по всей матрице)
content_copy Ссылка save Сохранить extension Виджет
Итак, для начала определимся с понятием треугольной, или ступенчатой матрицы:
Матрица имеет ступенчатый вид, если:
- Все нулевые строки матрицы стоят последними
- Первый ненулевой элемент строки всегда находится строго правее первого ненулевого элемента предыдущей строки
- Все элементы столбца под первым ненулевым элементом строки равны нулю (это впрочем следует из первых двух пунктов)
Пример ступенчатой матрицы:
1 0 2 5
0 3 0 0
0 0 0 4
Понятие треугольной матрицы более узкое, оно используется только для квадратных матриц (хотя я думаю, что это не строго), и формулируется проще: треугольная матрица — квадратная матрица, в которой все элементы ниже главной диагонали равны нулю. Строго говоря, это даже определение верхнетреугольной матрицы, но мы будем использовать его. Понятно, что такая верхнетреугольная матрица является также и ступенчатой.
Пример треугольной (верхнетреугольной) матрицы:
1 0 2 5
0 3 1 3
0 0 4 2
0 0 0 3
Кстати, определитель треугольной матрицы вычисляется простым перемножением ее диагональных элементов.
Чем же так интересны ступенчатые (и треугольные) матрицы, что к ним надо приводить все остальные? — спросите вы.
У них есть замечательной свойство, а именно, любую прямоугольную матрицу можно с помощью элементарных преобразований привести к ступенчатой форме.
Что же такое элементарные преобразования? — спросите вы.
Элементарными преобразованиями матрицы называют следующие операции:
- перестановка любых двух строк (столбцов) матрицы
- умножение любой строки (столбца) на призвольное, отличное от нуля, число
- сложение любой строки (столбца) с другой строкой (столбцом), умноженной (умноженным) на произвольное, отличное от нуля, число.
И что? — спросите вы.
А то, что элементарные преобразования матрицы сохраняют эквивалентность матриц. А если вспомнить, что системы линейных алгебраический уравнений (СЛАУ) записывают как раз в матричной форме, то это означает, что элементарные преобразования матрицы не изменяют множество решений системы линейных алгебраических уравнений, которую представляет эта матрица.
Приведя матрицу системы линейных уравнений AX=B к треугольной форме A’X = B’, то есть, с соответствующими преобразованиями столбца B, можно найти решение этой системы так называемым «обратным ходом».
Чтобы было понятно, используем треугольную матрицу выше и перепишем систему уравнений в более привычной форме (столбец B я придумал сам):
Понятно, что сначала мы найдем , потом, подставив его в предыдущее уравнение, найдем и так далее — двигаясь от последнего уравнения к первому. Это и есть обратный ход.
Алгоритм приведения матрицы к ступенчатой форме с помощью элементарных преобразований называют методом Гаусса. Метод Гаусса — классический метод решения систем линейных алгебраических уравнений.
Теперь про сам метод.
Собственно, как можно занулить переменную во втором уравнении? Вычтя из него первое, домноженное на коэффициент
Поясним на примере:
Зануляем во втором уравнении:
Во втором уравнении больше не содержится
Обобщенно алгоритм метода Гаусса можно представить следующим образом:
где N — число строк,
— i-тая строка,
— элемент, находящийся в i-той строке, j-том столбце
И все бы ничего, да и метод отличный, но. Дело все в делении на , присутствующем в формуле. Во-первых, если диагональный элемент будет равен нулю, то метод работать не будет. Во-вторых, в процессе вычисления будет накапливаться погрешность, и чем дальше, тем больше. Результат будет отличаться от точного.
Для уменьшения погрешности используют модификации метода Гаусса, которые основаны на том, что погрешность тем меньше, чем больше знаменатель дроби. Эти модификации — метод Гаусса с выбором максимума в столбце и метод Гаусса с выбором максимума по всей матрице. Как следует из названия, перед каждым шагом исключения переменной по столбцу (всей матрице) ищется элемент с максимальным значением и проводится перестановка строк (строк и столбцов), таким образом, чтобы он оказался на месте .
Но есть еще более радикальная модификация метода Гаусса, которая называется методом Барейса (Bareiss).
Как можно избавиться от деления? Например, умножив перед вычитанием строку на . Тогда вычитать надо будет строку , домноженную только на , без всякого деления.
.
Уже хорошо, но возникает проблема с ростом значений элементов матрицы в ходе вычисления.
Барейс предложил делить выражение выше на и показал, что если исходные элементы матрицы — целые числа, то результатом вычисления такого выражения тоже будет целое число. При этом принимается, что для нулевой строки .
При этом принимается, что для нулевой строки .
Кстати, то, что в случае целочисленных элементов исходной матрицы алгоритм Барейса приводит к треугольной матрице с целочисленными элементами, то есть без накопления погрешности вычислений — довольно важное свойство с точки зрения машинной арифметики.
Алгоритм Барейса можно представить следующим образом:
Алгоритм, аналогично методу Гаусса, также можно улучшить поиском максимума по столбцу(всей матрице) и перестановкой соответствующих строк (строк и столбцов).
★ Зануление — электротехника .. Информация
2. Ошибки в реализации зануления.
(Mistakes in the implementation of the vanishing)Иногда мне кажется, что заземление на отдельный контур, не связанный с нулевым проводом сети, лучше, потому что нет сопротивления длинного PEN-проводника от электроустановки потребителя до заземлителя КТП комплектные трансформаторные подстанции. это мнение ошибочно, потому что сопротивление заземления, особенно кустарного, гораздо больше сопротивления даже длинного провода. И замыкание фазы на заземленный таким образом корпус электроприбора, то ток замыкания из-за большого сопротивления местного заземления может быть недостаточно для срабатывания АВ прерыватель цепи или плавкий предохранитель, защищающий эту линию. В этом случае жилье будет находиться под потенциальной угрозой. кроме того, даже если использовать ПТР небольшой стоимости, вызванная тока замыкания на землю, все равно обеспечить требуемое время ПУЭ для автоматического отключения поврежденной линии практически невозможно.
Поэтому, до начала массового применения УЗО, заземление корпусов электрооборудования без зануления, что есть система заземления ТТ, не признать пункт. 1.7.39 (ПУЭ 1.7.39) -6:
В электроустановках до 1 кВ с глухозаземленной нейтралью или форм глюкозамин выводом источника однофазного тока, а также с глухозаземленной средней точкой в трехпроводных сетях постоянного тока должно быть выполнено зануление.
Распространенным заблуждением является утверждение, что согласно новой редакции ПУЭ п. 1.7.59, заземлением корпусов электрооборудования без зануления допускается, но только при обязательном применении УЗО пункт. 1.7.39 (ПУЭ 1.7.39) -7:
Мощность электрического напряжения до 1 кВ от источника с глухозаземленной нейтралью и с заземлением открытых проводящих частей с помощью заземлителя не подключен к нейтрали система ТТ, допускается только в случаях, когда условия электробезопасности в системе TN не могут быть обеспечены. для защиты при косвенном прикосновении в таких электроустановках должно быть автоматическое отключение питания с обязательным применением УЗО. при этом должно быть соблюдено условие: Ra * ИА ≤ 50 В, где НМА-ток срабатывания защитного устройства Ra — суммарное сопротивление заземлителя и заземляющего проводника, при применении УЗО для защиты нескольких токоприемников — заземляющего проводника наиболее удаленного электроприемника.
В пункте ПУЭ речь идет о системе ТТ. указывает, что в ТТ электрическая система безопасности в косвенным прикосновением обеспечивается УЗО. сети определяется состоянием нейтрали источника питания п. 1.7.3, в большинстве случаев трансформатора подстанции, а также способами подключения открытых проводящих частей оборудования к элементам защиты, которые четко определены для каждой системы — глухозаземленной нейтралью трансформатора или заземляющему устройству.
матрицы секционные — Prix | Aliexpress
Quel que soit l’objet de votre désir, la plateforme d’AliExpress est une véritable mine d’or. Une envie de матрицы секционные? N’allez pas plus loin! Nous proposons des milliers de produits dans toutes les catégories de vente, afin de satisfaire toutes vos envies. Des grandes marques aux vendeurs plus originaux, du luxe à l’entrée de gamme, vous trouverez TOUT sur AliExpress, avec un service de livraison rapide et fiable, des modes de paiement sûrs et pratiques, quel que soit le montant et la quantité de votre commande.
Sans oublier les économies dont vous pouvez bénéficier grâce aux prix les plus bas du marché et à des remises sensationnelles. Votre матрицы секционные va faire envie à tous vos proches, croyez-nous!»
AliExpress compare pour vous les différents fournisseurs et toutes les marques en vous informant des prix et des promotions en vigueur. Notre site regroupe également des commentaires de véritables clients, chaque produit étant noté selon plusieurs critères commerciaux. Tous les éléments sont réunis pour vous aider à prendre la meilleure décision, en fonction de vos besoins et de vos envies. Il vous suffit de suivre les conseils des millions de clients satisfaits par nos services.»
Alors n’attendez plus, offrez-vous votre/vos матрицы секционные! Qualité et petits prix garantis, il ne vous reste plus qu’à valider votre panier et à cliquer sur «Acheter maintenant». C’est simple comme bonjour. Et parce que nous adorons vous faire plaisir, nous avons même prévu des coupons pour rendre votre achat encore plus avantageux. Pensez à les récupérer pour obtenir ce(s) матрицы секционные à un prix imbattable.»
Chez AliExpress, rien ne nous rend plus fier que la lecture des retours positifs de notre chère clientèle, c’est pourquoi nous nous engageons à leur offrir le meilleur.
НОУ ИНТУИТ | Лекция | Умножение разреженных матриц
Аннотация: В лекции рассматриваются типовые алгоритмы, применяемые в работе с плотными и разреженными матрицами. Рассказывается о некоторых форматах хранения этих матриц. Рассматриваются основные свойства матриц, методы решения СЛАУ, прямые и итерационные методы.
Рассказывается о некоторых форматах хранения этих матриц. Рассматриваются основные свойства матриц, методы решения СЛАУ, прямые и итерационные методы.
Цель лекции: Основной целью лекции является применение полученные знания о разработке и отладке параллельных программ в реализации численных алгоритмов для работы с матрицами.
Прямые методы решения СЛАУ
Методы решения систем линейных алгебраических уравнений (СЛАУ) относятся к численным методам алгебры. При формальном подходе решение подобных задач не встречает затруднений: решение системы можно найти, раскрыв определители в формуле Крамера. Однако при непосредственном раскрытии определителей решение системы с n неизвестными требует арифметических операций; уже при n порядка 20 такое число операций недоступно для современных компьютеров. При сколько-нибудь больших n применение методов с таким порядком числа операций будет невозможно и в обозримом будущем. Другой причиной, по которой этот классический способ неприменим даже при малых n, является сильное влияние на окончательный результат округлений при вычислениях.
Методы решения алгебраических задач можно разделить на точные и итерационные. Классы задач, для решения которых обычно применяют методы этих групп, можно условно назвать соответственно классами задач со средним и большим числом неизвестных. Изменение объема и структуры памяти вычислительных систем, увеличение их быстродействия и развитие численных методов приводят к смещению границ применения методов в сторону систем более высоких порядков.
Например, в 80-х годах прошлого века точные методы применялись для решения систем до порядка 104, итерационные – до порядка 107, в 90-х – до порядков 105 и 108 соответственно. Современные суперкомпьютеры способны использовать точные методы при решении еще больших систем.
Мы будем рассматривать систему из n линейных алгебраических уравнений вида
| ( 7.1) |
В матричном виде система может быть представлена как
| ( 7.2) |
где есть вещественная матрица размера ; b и x — вектора из n элементов.
Под задачей решения системы линейных уравнений для заданных матрицы А и вектора b мы будем считать нахождение значения вектора неизвестных x, при котором выполняются все уравнения системы.
Метод исключения Гаусса
В первую очередь рассмотрим алгоритмыы, предназначенные для решения системы
| ( 7.3) |
с произвольной квадратной матрицей А. Основой для всех них служит широко известный метод последовательного исключения неизвестных, или же метод Гаусса.
Метод Гаусса основывается на возможности выполнения преобразований линейных уравнений, которые не меняют при этом решение рассматриваемой системы (такие преобразования носят наименование эквивалентных). К числу таких преобразований относятся:
К числу таких преобразований относятся:
- умножение любого из уравнений на ненулевую константу,
- перестановка уравнений,
- прибавление к уравнению любого другого уравнения системы.
Метод Гаусса включает последовательное выполнение двух этапов. На первом этапе, который называется прямой ход, исходная система линейных уравнений при помощи последовательного исключения неизвестных приводится к верхнему треугольному виду. При выполнении обратного хода (второй этап алгоритма) осуществляется определение значений неизвестных.
Последовательный алгоритм
Прямой ход состоит в последовательном исключении неизвестных в уравнениях решаемой системы линейных уравнений.
На итерации i, метода производится исключение неизвестной i для всех уравнений с номерами k, больших i(т.е.) Для этого из этих уравнений осуществляется вычитание строки i, умноженной на константу с тем, чтобы результирующий коэффициент при неизвестной в строках оказался нулевым – все необходимые вычисления могут быть определены при помощи соотношений:
| ( 7.4) |
где — множители Гаусса.
В итоге приходим к системе с верхней треугольной матрицей
При выполнении прямого хода метода Гаусса строка, которая используется для исключения неизвестных, носит наименование ведущей, а диагональный элемент ведущей строки называется ведущим элементом. Как можно заметить, выполнение вычислений является возможным только, если ведущий элемент имеет ненулевое значение. Более того, если ведущий элемент
Как можно заметить, выполнение вычислений является возможным только, если ведущий элемент имеет ненулевое значение. Более того, если ведущий элемент
Избежать подобной проблемы можно, если при выполнении каждой очередной итерации прямого хода метода Гаусса определить коэффициент с максимальным значением по абсолютной величине в столбце, соответствующем исключаемой неизвестной, т.е.
и выбрать в качестве ведущей строку, в которой этот коэффициент располагается (данная схема выбора ведущего значения носит наименование метода главных элементов).
Обратный ход алгоритма состоит в следующем. После приведения матрицы коэффициентов к верхнему треугольному виду становится возможным определение значений неизвестных. Из последнего уравнения преобразованной системы может быть вычислено значение переменной
, после этого из предпоследнего уравнения становится возможным определение переменной и т.д. В общем виде выполняемые вычисления при обратном ходе метода Гаусса могут быть представлены при помощи соотношений:Оценим трудоемкость метода Гаусса. При выполнении прямого хода число операций составит
Для выполнения обратного хода потребуется
Таким образом, общее время выполнения метода Гаусса при больших n можно оценить как
где время выполнения одной операции.
Параллельный алгоритм
При внимательном рассмотрении метода Гаусса можно заметить, что все вычисления сводятся к однотипным вычислительным операциям над строками матрицы коэффициентов системы линейных уравнений. Как результат, в основу параллельной реализации алгоритма Гаусса может быть положен принцип распараллеливания по данным. В качестве базовой подзадачи можно принять тогда все вычисления, связанные с обработкой одной строки матрицы A и соответствующего элемента вектора b. Рассмотрим общую схему параллельных вычислений и возникающие при этом информационные зависимости между базовыми подзадачами.
Как результат, в основу параллельной реализации алгоритма Гаусса может быть положен принцип распараллеливания по данным. В качестве базовой подзадачи можно принять тогда все вычисления, связанные с обработкой одной строки матрицы A и соответствующего элемента вектора b. Рассмотрим общую схему параллельных вычислений и возникающие при этом информационные зависимости между базовыми подзадачами.
Для выполнения прямого хода метода Гаусса необходимо осуществить итерацию по исключению неизвестных для преобразования матрицы коэффициентов A к верхнему треугольному виду. Выполнение итерации i, , прямого хода метода Гаусса включает ряд последовательных действий. Прежде всего, в самом начале итерации необходимо выбрать ведущую строку, которая при использовании метода главных элементов определяется поиском строки с наибольшим по абсолютной величине значением среди элементов столбца i, соответствующего исключаемой переменной . Зная ведущую строку, подзадачи выполняют вычитание строк, обеспечивая тем самым исключение соответствующей неизвестной .
При выполнении обратного хода метода Гаусса подзадачи выполняют необходимые вычисления для нахождения значения неизвестных. Как только какая-либо подзадача i, , определяет значение своей переменной , это значение должно быть использовано всеми подзадачам с номерами k, : подзадачи подставляют полученное значение новой неизвестной и выполняют корректировку значений для элементов вектора b.
Выделенные базовые подзадачи характеризуются одинаковой вычислительной трудоемкостью. Однако размер матрицы, описывающей систему линейных уравнений, является существенно большим, чем число потоков в программе (т.е.,), и базовые подзадачи можно укрупнить, объединив в рамках одной подзадачи несколько строк матрицы. При этом применение последовательной схемы разделения данных для параллельного решения систем линейных уравнений приведет к неравномерной вычислительной нагрузке между потоками: по мере исключения (на прямом ходе) или определения (на обратном ходе) неизвестных в методе Гаусса для большей части потоков все необходимые вычисления будут завершены и они окажутся простаивающими. Возможное решение проблемы балансировки вычислений может состоять в использовании ленточной циклической схемы для распределения данных между укрупненными подзадачами. В этом случае матрица A делится на наборы (полосы) строк вида
(см. рис. 7.1).
Возможное решение проблемы балансировки вычислений может состоять в использовании ленточной циклической схемы для распределения данных между укрупненными подзадачами. В этом случае матрица A делится на наборы (полосы) строк вида
(см. рис. 7.1).
Рис. 7.1. Ленточная схема
Сопоставив схему разделения данных и порядок выполнения вычислений в методе Гаусса, можно отметить, что использование циклического способа формирования полос позволяет обеспечить лучшую балансировку вычислительной нагрузки между подзадачами.
Итак, проведя анализ последовательного варианта алгоритма Гаусса, можно заключить, что распараллеливание возможно для следующих вычислительных процедур:
- поиск ведущей строки,
- вычитание ведущей строки из всех строк, подлежащих обработке,
- выполнение обратного хода.
Оценим трудоемкость рассмотренного параллельного варианта метода Гаусса. Пусть n есть порядок решаемой системы линейных уравнений, а p, , обозначает число потоков. При разработке параллельного алгоритма все вычислительные операции, выполняемые алгоритмом Гаусса, были распределены между потоками параллельной программы. Следовательно, время, необходимое для выполнения вычислений на этапе прямого хода, можно оценить как
Подставив выражение получим, что время выполнения вычислений для параллельного варианта метода Гаусса описывается выражением:
Теперь можно оценить величину накладных расходов, обусловленных организацией и закрытием параллельных секций. Пусть – время, необходимое на организацию и закрытие параллельной секции. Параллельная секция создается при каждом выборе ведущей строки, при выполнении вычитания ведущей строки из остальных строк линейной системы, подлежащих обработке, а также при выполнении каждой итерации обратного хода метода Гаусса. Таким образом, общее число параллельных секций составляет .
Таким образом, общее число параллельных секций составляет .
Сводя воедино все полученные оценки можно заключить, что время выполнения параллельного метода Гаусса описывается соотношением
| ( 7.5) |
Связь метода Гаусса и LU-разложения
LU-разложение — представление матрицы A в виде
| ( 7.6) |
где L — нижняя треугольная матрица с диагональными элементами, равными единице, а U — верхняя треугольная матрица с ненулевыми диагональными элементами. LU-разложение также называют LU-факторизацией. Известно [4], что LU-разложение существует и единственно, если главные миноры матрицы A отличны от нуля.
Алгоритм LU-разложения тесно связан с методом исключения Гаусса. В самом деле, пусть мы решаем систему уравнений вида (7.2). Непосредственно проверяется, что преобразования k-го шага метода Гаусса равносильны домножению системы (7.2) слева на матрицу
где — множители Гаусса из (7.4). Как было рассмотрено в п. 7.1.1, прямой ход метода Гаусса преобразует исходную систему уравнений к виду
с верхней треугольной матрицей U. Зная матрицы , можно записать матрицу U и вектор c как
Обозначим Можно непосредственно проверить, что
 intuit.ru/2010/edi»>Отсюда получаем .
intuit.ru/2010/edi»>Отсюда получаем .Таким образом, матрицу L можно получить как нижнюю треугольную матрицу коэффициентов Гаусса, а матрицу U — как верхнюю треугольную матрицу, получаемую в результате работы метода Гаусса. При этом очевидно, что трудоемкость получения LU-факторизации будет такой же-.
Рассмотренный нами алгоритм LU-факторизации реализован с помощью исключения по столбцу. Следует отметить, что можно сформулировать аналогичный алгоритм, основанный на исключении по строке. В самом деле, основная идея алгоритма с помощью исключения по столбцу заключается в том, что на i-й итерации ведущая строка с подходящими множителями вычитается из строк, лежащих ниже, чтобы занулить все элементы матрицы, расположенные в i-м столбце ниже диагонали. Между тем возможно и другое: на каждой i-й итерации можно вычитать из i-й строки все строки, расположенные выше, умноженные на подходящие коэффициенты, так, чтобы занулить все элементы i-й строки левее диагонали. При этом элементы матрицы L ниже главной диагонали и элементы матрицы U на главной диагонали и выше нее можно вычислять на месте матрицы А. Как и в случае исключения по столбцу, приведенная схема требует проведения операций
Рассмотрим теперь еще один способ LU-факторизаци, называемый компактной схемой. Пусть матрица допускает LU-разложение (7.6), где
т.е. при а при . Из соотношения (7.6) следует, что
Преобразуем эту сумму двумя способами:
Отсюда находим
Оценка числа операций данного алгоритма LUфакторизаци также составляет
Если разложение (7.6) получено, то решение системы (7.2) сводится к последовательному решению двух систем уравнений с треугольными матрицами (обратный ход)
(
7. 7) 7) |
Обратный ход требует операций.
Как следует из приведенных оценок, вычислительная сложность метода исключения Гаусса и метода LU-разложения одинакова. Однако если необходимо решить несколько систем с одинаковыми матрицами коэффициентов, но различными векторами свободных членов (правая часть СЛАУ), то метод LU-разложения окажется предпочтительным, так как в этом случае нет необходимости производить разложение матрицы коэффициентов многократно. Достаточно лишь сохранить полученные треугольные матрицы в памяти и, подставляя различные вектора свободных членов, получать решения методами прямой и обратной подстановки. Это позволит значительно сократить объем вычислений по сравнению с методом Гаусса.
Нейронные сети, или Как обучить искусственный интеллект — Интернет изнутри
Машинное обучение является не единственным, но одним из фундаментальных разделов искусственного интеллекта, занимающимся вопросами самостоятельного извлечения знаний интеллектуальной системой в процессе ее работы. Основу машинного обучения составляют так называемые искусственные нейронные сети, принцип работы которых напоминает работу биологических нейронов нервной системы животных и человека.
Технологии искусственного интеллекта все активнее используются в самых различных областях – от производственных процессов до финансовой деятельности. Популярные услуги техгигантов, такие как «Яндекс.Алиса», Google Translate, Google Photos и Google Image Search (AlexNet, GoogleNet) основаны на работе нейронных сетей.
Что такое нейронные сети и как они работают – об этом пойдет речь в статье.
Введение
У искусственного интеллекта множество определений. Под этим термином понимается, например, научное направление, в рамках которого ставятся и решаются задачи аппаратного или программного моделирования тех видов человеческой деятельности, которые традиционно считаются творческими или интеллектуальными, а также соответствующий раздел информатики, задачей которого является воссоздание с помощью вычислительных систем и иных искусственных устройств разумных рассуждений и действий, равно как и свойство систем выполнять «творческие» функции. Искусственный интеллект уже сегодня прочно вошел в нашу жизнь, он используется так или иначе во многих вещах, которые нас окружают: от смартфонов до холодильников, — и сферах деятельности: компании многих направлений, от IT и банков до тяжелого производства, стремятся использовать последние разработки для
Искусственный интеллект уже сегодня прочно вошел в нашу жизнь, он используется так или иначе во многих вещах, которые нас окружают: от смартфонов до холодильников, — и сферах деятельности: компании многих направлений, от IT и банков до тяжелого производства, стремятся использовать последние разработки для
повышения эффективности. Данная тенденция будет лишь усиливаться в будущем.
Машинное обучение является не единственным, но одним из основных разделов, фундаментом искусственного интеллекта, занимающимся вопросами самостоятельного извлечения знаний интеллектуальной системой в процессе ее работы. Зародилось это направление еще в середине XX века, однако резко возросший интерес направление получило с существенным развитием области математики, специализирующейся на нейронных сетях, после недавнего изобретения эффективных алгоритмов обучения таких сетей. Идея создания искусственных нейронных сетей была перенята у природы. В качестве примера и аналога была использована нервная система как животного, так и человека. Принцип работы искусственной нейронной сети соответствует алгоритму работы биологических нейронов.
Нейрон – вычислительная единица, получающая информацию и производящая над этой информацией какие-либо вычисления. Нейроны являются простейшей структурной единицей любой нейронной сети, из их множества, упорядоченного некоторым образом в слои, а в конечном счете – во всю сеть, состоят все сети. Все нейроны функционируют примерно одинаковым образом, однако бывают некоторые частные случаи нейронов, выполняющих специфические функции. Три основных типа нейронов:
Рис. 1. Основные типы нейронов.Входной – слой нейронов, получающий информацию (синий цвет на рис. 1).
Скрытый – некоторое количество слоев, обрабатывающих информацию (красный цвет на рис. 1).
Выходной – слой нейронов, представляющий результаты вычислений (зеленый цвет на рис. 1).
Помимо самих нейронов существуют синапсы. Синапс – связь, соединяющая выход одного нейрона со входом другого. Во время прохождения сигнала через синапс сигнал может усиливаться или ослабевать. Параметром синапса является вес (некоторый коэффициент, может быть любым вещественным числом), из-за которого информация, передающаяся от одного нейрона к другому, может изменяться. При помощи весов входная информация проходит обработку — и после мы получаем результат.
Во время прохождения сигнала через синапс сигнал может усиливаться или ослабевать. Параметром синапса является вес (некоторый коэффициент, может быть любым вещественным числом), из-за которого информация, передающаяся от одного нейрона к другому, может изменяться. При помощи весов входная информация проходит обработку — и после мы получаем результат.
На рис. 2 изображена математическая модель нейрона. На вход подаются числа (сигналы), после они умножаются на веса (каждый сигнал – на свой вес) и суммируются. Функция активации высчитывает выходной сигнал и подает его на выход.
Сама идея функции активации также взята из биологии. Представьте себе ситуацию: вы подошли и положили палец на конфорку варочной панели. В зависимости от сигнала, который при этом поступит от пальца по нервным окончаниям в мозг, в нейронах вашего мозга будет принято решение: пропускать ли сигнал дальше по нейронным связям, давая посыл мышцам отдернуть палец от горячей конфорки, или не пропускать сигнал, если конфорка холодная и палец можно оставить. Математический аналог функции активации имеет то же назначение. Таким образом, функция активации позволяет проходить или не проходить сигналам от нейрона к нейронам в зависимости от информации, которую они передают. Т.е. если информация является важной, то функция пропускает ее, а если информации мало или она недостоверна, то функция активации не позволяет ей пройти дальше.
Таблица 1. Популярные разновидности активационных функций искусственного нейронаВ таблице 1 представлены некоторые виды активационных функций нейрона. Простейшей разновидностью функции активации является пороговая. Как следует из названия, ее график представляет из себя ступеньку. Например, если поступивший в нейрон суммарный сигнал от предыдущих нейронов меньше 0, то в результате применения функции активации сигнал полностью «тормозится» и дальше не проходит, т.е. на выход данного нейрона (и, соответственно, входы последующих нейронов) подается 0. Если же сигнал >= 0, то на выход данного нейрона подается 1.
Если же сигнал >= 0, то на выход данного нейрона подается 1.
Функция активации должна быть одинаковой для всех нейронов внутри одного слоя, однако для разных слоев могут выбираться разные функции активации. В искусственных нейронных сетях выбор функции обуславливается областью применения и является важной исследовательской задачей для специалиста по машинному обучению.
Нейронные сети набирают все большую популярность и область их использования также расширяется. Список некоторых областей, где применяются искусственные нейронные сети:
- Ввод и обработка информации. Распознавание текстов на фотографиях и различных документах, распознавание голосовых команд, голосовой ввод текста.
- Безопасность. Распознавание лиц и различных биометрических данных, анализ трафика в сети, обнаружение подделок.
- Интернет. Таргетинговая реклама, капча, составление новостных лент, блокировка спама, ассоциативный поиск информации.
- Связь. Маршрутизация пакетов, сжатие видеоинформации, увеличение скорости кодирования и декодирования информации.
Помимо перечисленных областей, нейронные сети применяются в робототехнике, компьютерных и настольных играх, авионике, медицине, экономике, бизнесе и в различных политических и социальных технологиях, финансово-экономическом анализе.
Архитектуры нейронных сетей
Архитектур нейронных сетей большое количество, и со временем появляются новые. Рассмотрим наиболее часто встречающиеся базовые архитектуры.
Персептрон
Рис. 3. Пример архитектуры персептрона.Персептрон – это простейшая модель нейросети, состоящая из одного нейрона. Нейрон может иметь произвольное количество входов (на рис. 3 изображен пример вида персептрона с четырьмя входами), а один из них обычно тождественно равен 1. Этот единичный вход называют смещением, его использование иногда бывает очень удобным. Каждый вход имеет свой собственный вес. При поступлении сигнала в нейрон, как и было описано выше, вычисляется взвешенная сумма сигналов, затем к сигналу применяется функция активации и сигнал передается на выход. Такая
Такая
простая на первый взгляд сеть, всего из одного-единственного нейрона, способна, тем не менее, решать ряд задач: выполнять простейший прогноз, регрессию данных и т.п., а также моделировать поведение несложных функций. Главное для эффективности работы этой сети – линейная разделимость данных.
Для читателей, немного знакомых с таким разделом как логика, будут знакомы логическое И (умножение) и логическое ИЛИ (сложение). Это булевы функции, принимающие значение, равное 0, всегда, кроме одного случая, для умножения, и, наоборот, значения, равные 1, всегда, кроме одного случая, для сложения. Для таких функций всегда можно провести прямую (или гиперплоскость в многомерном пространстве), отделяющие 0 значения от 1. Это и называют линейной разделимостью объектов. Тогда подобная модель сможет решить поставленную задачу классификации и сформировать базовый логический элемент. Если же объекты линейно неразделимы, то сеть из одного нейрона с ними не справится. Для этого существуют более сложные архитектуры нейронных сетей, в конечном счете, тем не менее, состоящие из множества таких персептронов, объединенных в слои.
Многослойный персептрон
Слоем называют объединение нейронов, на схемах, как правило, слои изображаются в виде одного вертикального ряда (в некоторых случаях схему могут поворачивать, и тогда ряд будет горизонтальным). Многослойный персептрон является обобщением однослойного персептрона. Он состоит из некоторого множества входных узлов, нескольких скрытых слоев вычислительных
нейронов и выходного слоя (см. рис. 4).
Отличительные признаки многослойного персептрона:
- Все нейроны обладают нелинейной функцией активации, которая является дифференцируемой.
- Сеть достигает высокой степени связности при помощи синаптических соединений.
- Сеть имеет один или несколько скрытых слоев.
Такие многослойные сети еще называют глубокими. Эта сеть нужна для решения задач, с которыми не может справиться персептрон. В частности, линейно неразделимых задач. В действительности, как следствие из теоремы Колмогорова, именно многослойный персептрон является единственной универсальной нейронной сетью, универсальным аппроксиматором, способным решить любую задачу. Возможно, не самым эффективным способом, который могли бы обеспечить более узкопрофильные нейросети, но все же решить.
В частности, линейно неразделимых задач. В действительности, как следствие из теоремы Колмогорова, именно многослойный персептрон является единственной универсальной нейронной сетью, универсальным аппроксиматором, способным решить любую задачу. Возможно, не самым эффективным способом, который могли бы обеспечить более узкопрофильные нейросети, но все же решить.
Именно поэтому, если исследователь не уверен, нейросеть какого вида подходит для решения стоящей перед ним задачи, он выбирает сначала многослойный персептрон.
Сверточная нейронная сеть (convolution neural network)
Сверточная нейронная сеть – сеть, которая обрабатывает передаваемые данные не целиком, а фрагментами. Данные последовательно обрабатываются, а после передаются дальше по слоям. Сверточные нейронные сети состоят из нескольких типов слоев: сверточный слой, субдискретизирующий слой, слой полносвязной сети (когда каждый нейрон одного слоя связан с каждым нейроном следующего – полная связь). Слои свертки и подвыборки (субдискретизации) чередуются и их набор может повторяться несколько раз (см. рис. 5). К конечным слоям часто добавляют персептроны, которые служат для последующей обработки данных.
Рис. 5. Архитектура сверточной нейронной сети.Название архитектура сети получила из-за наличия операции свёртки, суть которой в том, что каждый фрагмент изображения умножается на матрицу (ядро) свёртки поэлементно, а результат суммируется и записывается в аналогичную позицию выходного изображения. Необходимо это для перехода от конкретных особенностей изображения к более абстрактным деталям, и далее – к
ещё более абстрактным, вплоть до выделения понятий высокого уровня (присутствует ли что-либо искомое на изображении).
Сверточные нейронные сети решают следующие задачи:
- Классификация. Пример: нейронная сеть определяет, что или кто находится на изображении.
- Детекция. Пример: нейронная сеть определяет, что/кто и где находится на изображении.
- Сегментация.
 Пример: нейронная сеть может определить каждый пиксель изображения и понять, к чему он относится.
Пример: нейронная сеть может определить каждый пиксель изображения и понять, к чему он относится.
 Пример: нейронная сеть может определить каждый пиксель изображения и понять, к чему он относится.
Пример: нейронная сеть может определить каждый пиксель изображения и понять, к чему он относится.Описанные сети относятся к сетям прямого распространения. Наряду с ними существуют нейронные сети, архитектуры которых имеют в своем составе связи, по которым сигнал распространяется в обратную сторону.
Рекуррентная нейронная сеть
Рекуррентная нейронная сеть – сеть, соединения между нейронами которой образуют ориентированный цикл. Т.е. в сети имеются обратные связи. При этом информация к нейронам может передаваться как с предыдущих слоев, так и от самих себя с предыдущей итерации (задержка). Пример схемы первой рекуррентной нейронной сети (НС Хопфилда) представлен на рис. 6.
Рис. 6. Архитектура рекуррентной нейронной сети.Характеристики сети:
- Каждое соединение имеет свой вес, который также является приоритетом.
- Узлы подразделяются на два типа: вводные (слева) и скрытые (1, 2, … K).
- Информация, находящаяся в нейронной сети, может передаваться как по прямой, слой за слоем, так и между нейронами.
Такие сети еще называют «памятью» (в случае сети Хопфилда – автоассоциативной; бывают также гетероассоциативные (сеть Коско – развитие сети Хопфилда) и другие). Почему? Если подать данной сети на вход некие «образцы» – последовательности кодов (к примеру, 1000001, 0111110 и 0110110) — и обучить ее на запоминание этих образцов, настроив веса синапсов сети определенным образом при помощи правила Хебба3, то затем, в процессе функционирования, сеть сможет «узнавать» запомненные образы и выдавать их на выход, в том числе исправляя искаженные поданные на вход образы. К примеру, если после обучения такой сети я подам на вход 1001001, то сеть узнает и исправит запомненный образец, выдав на выходе 1000001. Правда, эта нейронная сеть не толерантна к поворотам и сдвигам образов, и все же для первой нейронной сети своего класса сеть весьма интересна.
Таким образом, особенность рекуррентной нейронной сети состоит в том, что она имеет «области внимания». Данная область позволяет задавать фрагменты передаваемых данных, которым требуется усиленная обработка.
Данная область позволяет задавать фрагменты передаваемых данных, которым требуется усиленная обработка.
Информация в рекуррентных сетях со временем теряется со скоростью, зависящей от активационных функций. Данные сети на сегодняшний день нашли свое применение в распознавании и обработке текстовых данных. Об этом речь пойдет далее.
Самоорганизующаяся нейронная сеть
Пример самоорганизующейся нейронной сети – сеть Кохонена. В процессе обучения осуществляется адаптация сети к поставленной задаче. В представленной сети (см. рис. 7) сигнал идет от входа к выходу в прямом направлении. Структура сети имеет один слой нейронов, которые не имеют коэффициентов смещения (тождественно единичных входов). Процесс обучения сети происходит при помощи метода последовательных приближений. Нейронная сеть подстраивается под закономерности входных данных, а не под лучшее значение на выходе. В результате обучения сеть находит окрестность, в которой находится лучший нейрон. Сеть функционирует по принципу «победитель получает все»: этот самый лучший нейрон в итоге на выходе будет иметь 1, а остальные нейроны, сигнал на которых получился меньше, 0. Визуализировать это можно так: представьте, что правый ряд нейронов, выходной, на
рис. 7 – это лампочки. Тогда после подачи на вход сети данных после их обработки на выходе «зажжется» только одна лампочка, указывающая, куда относится поданный объект. Именно поэтому такие сети часто используются в задачах кластеризации и классификации.
Алгоритмы обучения нейронных сетей
Чтобы получить решение поставленной задачи с использованием нейронной сети, вначале требуется сеть обучить (рис. 8). Процесс обучения сети заключается в настройке весовых коэффициентов связей между нейронами.
Рис. 8. Процесс обучения нейронной сети.Алгоритмы обучения для нейронной сети бывают с
учителем и без.
- С учителем: предоставление нейронной сети некоторой выборки обучающих примеров. Образец подается на вход, после происходит обработка внутри нейронной сети и рассчитывается выходной сигнал, сравнивающийся с соответствующим значением целевого вектора (известным нам «правильным ответом» для каждого из обучающих примеров). Если ответ сети не совпадает с требуемым, производится коррекция весов сети, напрямую зависящая от того, насколько отличается ответ сети от правильного (ошибка). Правило этой коррекции называется правилом Видроу-Хоффа и является прямой пропорциональностью коррекции каждого веса и размера ошибки, производной функции активации и входного сигнала нейрона. Именно после изобретения и доработок алгоритма распространения этой ошибки на все нейроны скрытых слоев глубоких нейронных сетей эта область искусственного интеллекта вернула к себе интерес.
- Без учителя: алгоритм подготавливает веса сети таким образом, чтобы можно было получить согласованные выходные векторы, т.е. предоставление достаточно близких векторов будет давать похожие выходы. Одним из таких алгоритмов обучения является правило Хебба, по которому настраивается перед работой матрица весов, например, рекуррентной сети Хопфилда.
 Образец подается на вход, после происходит обработка внутри нейронной сети и рассчитывается выходной сигнал, сравнивающийся с соответствующим значением целевого вектора (известным нам «правильным ответом» для каждого из обучающих примеров). Если ответ сети не совпадает с требуемым, производится коррекция весов сети, напрямую зависящая от того, насколько отличается ответ сети от правильного (ошибка). Правило этой коррекции называется правилом Видроу-Хоффа и является прямой пропорциональностью коррекции каждого веса и размера ошибки, производной функции активации и входного сигнала нейрона. Именно после изобретения и доработок алгоритма распространения этой ошибки на все нейроны скрытых слоев глубоких нейронных сетей эта область искусственного интеллекта вернула к себе интерес.
Образец подается на вход, после происходит обработка внутри нейронной сети и рассчитывается выходной сигнал, сравнивающийся с соответствующим значением целевого вектора (известным нам «правильным ответом» для каждого из обучающих примеров). Если ответ сети не совпадает с требуемым, производится коррекция весов сети, напрямую зависящая от того, насколько отличается ответ сети от правильного (ошибка). Правило этой коррекции называется правилом Видроу-Хоффа и является прямой пропорциональностью коррекции каждого веса и размера ошибки, производной функции активации и входного сигнала нейрона. Именно после изобретения и доработок алгоритма распространения этой ошибки на все нейроны скрытых слоев глубоких нейронных сетей эта область искусственного интеллекта вернула к себе интерес.Рассмотрим теперь, какие архитектуры сетей являются наиболее востребованными сейчас, каковы особенности использования нейросетей на примерах известных крупных проектов.
Рекуррентные сети на примерах Google и «Яндекса»
Уже упоминавшаяся выше рекуррентная нейронная сеть (RNN) – сеть, которая обладает кратковременной «памятью», из-за чего может быстро производить анализ последовательностей различной длины. RNN разбивает потоки данных на части и производит оценку связей между ними.
Сеть долговременной краткосрочной памяти (Long shortterm memory – LSTM) – сеть, которая появилась в результате развития RNN-сетей. Это интересная модификация RNN-сетей, позволяющая сети не просто «держать контекст», но и умеющая «видеть» долговременные зависимости. Поэтому LSTM подходит для прогнозирования различных изменений при помощи экстраполяции (выявление тенденции на основе данных), а также в любых задачах, где важно умение «держать контекст», особенно хорошо подвластное для данной нейросети.
Форма рекуррентных нейронных сетей представляет собой несколько повторяющихся модулей. В стандартном виде эти модули имеют простую структуру. На рисунке 9 изображена сеть, которая имеет в одном из слоев гиперболический тангенс в качестве функции активации.
Рис. 10. Модуль LSTM-сети.
LSTM также имеет цепочечную структуру. Отличие состоит в том, что сеть имеет четыре слоя, а не один (рис. 10). Главным отличием LSTM-сети является ее клеточное состояние (или состояние ячейки), которое обозначается горизонтальной линией в верхней части диаграммы и по которой проходит информация (рис. 11). Это самое состояние ячейки напоминает ленту конвейера: она проходит напрямую через всю цепочку, участвуя в некоторых преобразованиях. Информация может как «течь» по ней, не подвергаясь изменениям, так и быть подвергнута преобразованиям со стороны нейросети7. (Представьте себе линию контроля на конвейере: изделия продвигаются на ленте перед сотрудником контроля, который лишь наблюдает за ними, но если ему что-то покажется важным или подозрительным, он может вмешаться).
Рис. 11. Клеточное состояние LSTM-модуля.LSTM имеет способность удалять или добавлять информацию к клеточному состоянию. Данная способность осуществляется при помощи вентилей, которые регулируют процессы взаимодействия с информацией. Вентиль – возможность выборочно пропускать информацию. Он состоит из сигмоидного слоя нейронной сети и операции поточечного умножения (рис. 12).
Рис. 12. Вентиль.Сигмоидный слой (нейроны с сигмоидальной функцией активации) подает на выход числа между нулем и единицей, описывая таким образом, насколько каждый компонент должен быть пропущен сквозь вентиль. Ноль – «не пропускать вовсе», один – «пропустить все». Таких «фильтров» в LSTM-сети несколько. Для чего сети нужна эта способность: решать, что важно, а что нет? Представьте себе следующее: сеть переводит предложение и в какой-то момент ей предстоит перевести с английского языка на русский, скажем, местоимение, прилагательное или причастие. Для этого сети необходимо, как минимум, помнить род и/или число предыдущего существительного, к которому переводимое слово относится. Однако как только мы встретим новое существительное, род предыдущего можно забыть. Конечно, это очень упрощенный пример, тем не
Для этого сети необходимо, как минимум, помнить род и/или число предыдущего существительного, к которому переводимое слово относится. Однако как только мы встретим новое существительное, род предыдущего можно забыть. Конечно, это очень упрощенный пример, тем не
менее, он позволяет понять трудность принятия решения: какая информация еще важна, а какую уже можно забыть. Иначе говоря, сети нужно решить, какая информация будет храниться в состоянии ячейки, а затем – что на выходе из нее будет выводить.
Примеры использования нейронных сетей
Мы рассмотрели основные типы нейронных систем и познакомились с принципами их работы. Остановимся теперь на их практическом применении в системах Google Translate, «Яндекс.Алиса», Google Photos и Google Image Search (AlexNet, GoogleNet).
LSTM в Google Translate
Google-переводчик в настоящее время основан на методах машинного обучения и использует принцип работы LSTM-сетей. Система производит вычисления, чтобы понять значение слова или фразы, основываясь на предыдущих значениях в последовательности (контексте). Такой алгоритм помогает системе понимать контекст предложения и верно подбирать перевод среди различных вариантов. Еще несколько лет назад Google Translate работал на основе статистического машинного перевода – это разновидность перевода, где перевод генерируется на основе статистических моделей (бывают: по словам, по фразам, по синтаксису и т.д.), а параметры этих моделей являются результатами анализа корпусов текстов двух выбранных для перевода языков. Эти статистические модели обладали большим быстродействием, однако их эффективность ниже. Общий прирост качества перевода после внедрения системы на основе нейросетей в Google-переводчик составил, казалось бы, не очень много – порядка 10%, однако для отдельных языковых пар эффективность перевода достигла 80-90%,
вплотную приблизившись к оценкам качества человеческого перевода. «Платой» за такое качество перевода является сложность построения, обучения и перенастройки системы на основе нейросети: она занимает недели. Вообще для современных глубоких нейронных сетей, использующихся в таких крупных проектах, в порядке вещей обучение, занимающее дни и недели.
Вообще для современных глубоких нейронных сетей, использующихся в таких крупных проектах, в порядке вещей обучение, занимающее дни и недели.
Рассмотрим LSTM-сеть переводчика (GNMT) подробнее. Нейронная сеть переводчика имеет разделение на два потока (см. рис. 13). Первый поток нейронной сети (слева) является анализирующим и состоит из восьми слоев. Данный поток помогает разбивать фразы или предложения на несколько смысловых частей, а после производит их анализ. Сеть позволяет читать предложения в двух направлениях, что помогает лучше понимать контекст. Также она занимается формированием модулей внимания, которые позволяют второму потоку определять ценности отдельно взятых смысловых фрагментов.
Второй поток нейронной сети (справа) является синтезирующим. Он позволяет вычислять самый подходящий вариант для перевода, основываясь на контексте и модулях внимания (показаны голубым цветом).
В системе нейронной сети самым маленьким элементом является фрагмент слова. Это позволяет сфокусировать вычислительную мощность на контексте предложения, что обеспечивает высокую скорость и точность переводчика. Также анализ фрагментов слова сокращает риски неточного перевода слов, которые имеют суффиксы, префиксы и окончания.
LSTM в «Яндекс.Алисе»
Компания «Яндекс» также использует нейросеть типа LSTM в продукте «Яндекс.Алиса». На рисунке 14 изображено взаимодействие пользователя с системой. После вопроса пользователя информация передается на сервер распознавания, где она преобразуется в текст. Затем текст поступает в классификатор интентов (интент (от англ. intent) – намерение, цель пользователя, которое он вкладывает в запрос), где при помощи машинного обучения анализируется. После анализа интентов они поступают на семантический теггер (tagger) – модель, которая позволяет выделить полезную и требующуюся информацию из предложения. Затем полученные результаты структурируются и передаются в модуль dialog manager, где обрабатывается полученная информация и генерируется ответ.
LSTM-сети применяются в семантическом теггере. В этом модуле используются двунаправленные LSTM с attention. На этом этапе генерируется не только самая вероятная гипотеза, потому что в зависимости от диалога могут потребоваться и другие. От состояния диалога в dialog manager происходит повторное взвешивание гипотез. Сети с долговременной памятью помогают лучше вести диалог с пользователем, потому что могут помнить предыдущие сообщения и более точно генерировать ответы, а также они помогают разрешать много проблемных ситуаций. В ходе диалога нейронная сеть может убирать слова, которые не несут никакой важной информации, а остальные анализировать и предоставлять ответ9. Для примера на рис. 14 результат работы системы будет следующим. Сначала речь пользователя в звуковом формате будет передана на сервер распознавания, который выполнит лексический анализ (т.е. переведет сказанное в текст и разобьет его на слова – лексемы), затем классификатор интентов выполнит уже роль семантического анализа (понимание смысла того, что было сказано; в данном случае – пользователя интересует погода), а семантический теггер выделит полезные элементы информации: теггер выдал бы, что завтра – это дата, на которую нужен прогноз погоды. В итоге данного анализа запроса пользователя будет составлено внутреннее представление запроса – фрейм, в котором будет указано, что интент – погода, что погода нужна на +1 день от текущего дня, а где – неизвестно. Этот фрейм попадет в диалоговый менеджер, который хранит тот самый контекст беседы и будет принимать на основе хранящегося контекста решение, что делать с этим запросом. Например, если до этого беседа не происходила, а для станции с «Яндекс.Алисой» указана геолокация г. Москва, то менеджер получит через специальный интерфейс (API) погоду на завтра в Москве, отправит команду на генерацию текста с этим прогнозом, после чего тот будет передан в синтезатор речи помощника. Если же Алиса до этого вела беседу с пользователем о достопримечательностях Парижа, то наиболее вероятно, что менеджер учтет это и либо уточнит у пользователя информацию о месте, либо сразу сообщит о погоде в Париже. Сам диалоговый менеджер работает на основе скриптов (сценариев обработки запросов) и правил, именуемых form-filling. Вот такой непростой набор технических решений, методов, алгоритмов и систем кроется за фасадом, позволяющим пользователю спросить и узнать ответ на простой бытовой вопрос или команду.
Сам диалоговый менеджер работает на основе скриптов (сценариев обработки запросов) и правил, именуемых form-filling. Вот такой непростой набор технических решений, методов, алгоритмов и систем кроется за фасадом, позволяющим пользователю спросить и узнать ответ на простой бытовой вопрос или команду.
Свёрточные нейронные сети, используемые для классификации изображений, на примере Google Photos и Google Image Search
Задача классификации изображений – это получение на вход начального изображения и вывод его класса (стол, шкаф, кошка, собака и т.д.) или группы вероятных классов, которая лучше всего характеризует изображение. Для людей это совершенно естественно и просто: это один из первых навыков, который мы осваиваем с рождения. Компьютер лишь «видит» перед собой пиксели изображения, имеющие различный цвет и интенсивность. На сегодня задача классификации объектов, расположенных на изображении, является основной для области компьютерного зрения. Данная область начала активно развиваться с 1970-х, когда компьютеры стали достаточно мощными, чтобы оперировать большими объёмами данных. До развития нейронных сетей задачу классификации изображений решали с помощью специализированных алгоритмов. Например, выделение границ изображения с помощью фильтра Собеля и фильтра Шарра или использование гистограмм градиентов10. С появлением более мощных GPU, позволяющих значительно эффективнее обучать нейросеть, применение нейросетей в сфере компьютерного зрения значительно возросло.
В 1988 году Ян Лекун предложил свёрточную архитектуру нейросети, нацеленную на классификацию изображений. А в 2012 году сеть AlexNet, построенная по данной архитектуре, заняла первое место в конкурсе по распознаванию изображений ImageNet, имея ошибку распознавания равную 15,3%12. Свёрточная архитектура нейросети использует некоторые особенности биологического распознавания образов, происходящих в мозгу человека. Например, в мозгу есть некоторые группы клеток, которые активируются, если в определённое поле зрения попадает горизонтальная или вертикальная граница объекта. Данное явление обнаружили Хьюбель и Визель в 1962 году. Поэтому, когда мы смотрим на изображение, скажем, собаки, мы можем отнести его к конкретному классу, если у изображения есть характерные особенности, которые можно идентифицировать, такие как лапы или четыре ноги. Аналогичным образом компьютер может выполнять классификацию изображений через поиск характеристик базового уровня, например, границ и искривлений, а затем — с помощью построения более абстрактных концепций через группы сверточных слоев.
Данное явление обнаружили Хьюбель и Визель в 1962 году. Поэтому, когда мы смотрим на изображение, скажем, собаки, мы можем отнести его к конкретному классу, если у изображения есть характерные особенности, которые можно идентифицировать, такие как лапы или четыре ноги. Аналогичным образом компьютер может выполнять классификацию изображений через поиск характеристик базового уровня, например, границ и искривлений, а затем — с помощью построения более абстрактных концепций через группы сверточных слоев.
Рассмотрим подробнее архитектуру и работу свёрточной нейросети (convolution neural network) на примере нейросети AlexNet (см. рис. 15). На вход подаётся изображение 227х227 пикселей (на рисунке изображено желтым), которое необходимо классифицировать (всего 1000 возможных классов). Изображение цветное, поэтому оно разбито по трём RGB-каналам. Наиболее важная операция – операция свёртки.
Операция свёртки (convolution) производится над двумя матрицами A и B размера [axb] и [cxd], результатом которой является матрица С размера
, где s – шаг, на который сдвигают матрицу B. Вычисляется результирующая матрица следующим образом:
см. рис. 16.Рисунок 16. Операция свёртки15: Исходная матрица A обозначена голубым цветом (имеет большую размерность), ядро свертки – матрица B — обозначена темно-синим цветом и перемещается по матрице A; результирующая матрица изображена зеленым, при этом соответствующая каждому шагу свертки результирующая ячейка отмечена темно-зеленым.
Рис. 16. Операция свёртки.Чем больше результирующий элемент ci,j,, тем более похожа область матрицы A на матрицу B. A называют изображением, а B – ядром или фильтром. Обычно шаг смещения B равен s = 1. Если увеличить шаг смещения, можно добиться уменьшения влияния соседних пикселей друг на друга в сумме (уменьшить рецептивное поле восприятия нейросети), в подавляющем большинстве случаев шаг оставляют равным 1. На рецептивное поле также влияет и размер ядра свёртки. Как видно из рис. 16, при свёртке результат теряет в размерности по сравнению с матрицей A. Поэтому, чтобы избежать данного явления, матрицу A дополняют ячейками (padding). Если этого не сделать, данные при переходе на следующие слои будут теряться слишком быстро, а информация о границах слоя будет неточной.
На рецептивное поле также влияет и размер ядра свёртки. Как видно из рис. 16, при свёртке результат теряет в размерности по сравнению с матрицей A. Поэтому, чтобы избежать данного явления, матрицу A дополняют ячейками (padding). Если этого не сделать, данные при переходе на следующие слои будут теряться слишком быстро, а информация о границах слоя будет неточной.
Таким образом, свёртка позволяет одному нейрону отвечать за определённый набор пикселей в изображении. Весовыми коэффициентами являются коэффициенты фильтра, а входными переменными – интенсивность свечения пикселя плюс параметр смещения.
Данный пример свёртки (см. рис. 16) был одномерным и подходит, например, для черно-белого изображения. В случае цветного изображения операция свёртки происходит следующим образом: в один фильтр включены три ядра, для каждого канала RGB соответственно, над каждым каналом операция свёртки происходит идентично примеру выше, затем три результирующие матрицы поэлементно складываются — и получается результат работы одного
фильтра – карта признаков.
Эта на первый взгляд непростая с математической точки зрения процедура нужна для выделения тех самых границ и искривлений – контуров изображения, при помощи которых, по аналогии с мозгом человека, сеть должна понять, что же изображено на картинке. Т.е. на карте признаков будут содержаться выделенные характеристические очертания детектированных объектов. Эта карта признаков будет являться результатом работы чередующихся слоев свертки и пулинга (от англ. pooling, или иначе – subsampling layers). Помните, в разделе описания концепции архитектуры сверточных сетей мы говорили, что эти слои чередуются и их наборы могут повторяться несколько раз (см. рис. 5)? Для чего это нужно? После свертки, как мы знаем, выделяются и «заостряются» некие характеристические черты анализируемого изображения (матрицы пикселей) путем увеличения значений соответствующих ядру ячеек матрицы и «занулению» значений других. При операции субдискретизации, или пулинга, происходит уменьшение размерности сформированных отдельных карт признаков. Поскольку для сверточных нейросетей считается, что информация о факте наличия искомого признака важнее точного знания его координат на изображении, то из нескольких соседних нейронов карты признаков выбирается максимальный и принимается за один нейрон уплотнённой карты признаков меньшей размерности. За счёт данной операции, помимо ускорения дальнейших вычислений, сеть становится также более инвариантной к масштабу входного изображения, сдвигам и поворотам изображений. Данное чередование слоев мы видим и для данной сети AlexNet (см. рис. 15), где слои свертки (обозначены CONV) чередуются с пулингом (обозначены эти слои как POOL), при этом следует учитывать, что операции свертки тем ресурсозатратнее, чем больше размер ядра свертки (матрицы B на рис. 16), поэтому иногда, когда требуется свертка с ядром достаточно большой размерности, ее заменяют на две и более последовательных свертки с ядром меньших
При операции субдискретизации, или пулинга, происходит уменьшение размерности сформированных отдельных карт признаков. Поскольку для сверточных нейросетей считается, что информация о факте наличия искомого признака важнее точного знания его координат на изображении, то из нескольких соседних нейронов карты признаков выбирается максимальный и принимается за один нейрон уплотнённой карты признаков меньшей размерности. За счёт данной операции, помимо ускорения дальнейших вычислений, сеть становится также более инвариантной к масштабу входного изображения, сдвигам и поворотам изображений. Данное чередование слоев мы видим и для данной сети AlexNet (см. рис. 15), где слои свертки (обозначены CONV) чередуются с пулингом (обозначены эти слои как POOL), при этом следует учитывать, что операции свертки тем ресурсозатратнее, чем больше размер ядра свертки (матрицы B на рис. 16), поэтому иногда, когда требуется свертка с ядром достаточно большой размерности, ее заменяют на две и более последовательных свертки с ядром меньших
размерностей. (Об этом мы поговорим далее.) Поэтому на рис. 15 мы можем увидеть участок архитектуры AlexNet, на котором три слоя CONV идут друг за другом.
Самая интересная часть в сети – полносвязный слой в конце. В этом слое по вводным данным (которые пришли с предыдущих слоев) строится и выводится вектор длины N, где N – число классов, по которым мы бы хотели классифицировать изображение, из них программа выбирает нужный. Например, если мы хотим построить сеть по распознаванию цифр, у N будет значение 10, потому что цифр всего 10. Каждое число в этом векторе представляет собой вероятность конкретного класса. Например, если результирующий вектор для распознавания цифр это [0 0.2 0 0.75 0 0 0 0 0.05], значит существует 20% вероятность, что на изображении «1», 75% вероятность – что «3», и 5% вероятность – что «9». Если мы хотим сеть по распознаванию букв латинского алфавита, то N должно быть равным 26 (без учета регистра), а если и буквы, и цифры вместе, то уже 36. И т.д. Конечно, это очень упрощенные примеры. В сети AlexNet конечная размерность выхода (изображена на рис. 15 зеленым) — 1000, а перед этим идут еще несколько полносвязных слоев с размерностями входа 9216 и выхода 4096 и обоими параметрами 4096 (изображены оранжевым и отмечены FC – full connected — на рисунке).
И т.д. Конечно, это очень упрощенные примеры. В сети AlexNet конечная размерность выхода (изображена на рис. 15 зеленым) — 1000, а перед этим идут еще несколько полносвязных слоев с размерностями входа 9216 и выхода 4096 и обоими параметрами 4096 (изображены оранжевым и отмечены FC – full connected — на рисунке).
Способ, с помощью которого работает полносвязный слой, – это обращение к выходу предыдущего слоя (который, как мы помним, должен выводить высокоуровневые карты свойств) и определение свойств, которые больше связаны с определенным классом. Поэтому в результате работы окончания сверточной сети по поданному на вход изображению с лужайкой, на которой, скажем, собака гоняется за птичкой, упрощенно можно сказать, что результатом может являться следующий вывод:
[dog (0.6), bird (0.35), cloud (0.05)].
Свёрточная нейронная сеть GoogleNet
В 2014 году на том же соревновании ImageNet, где была представлена AlexNet, компания Google показала свою свёрточную нейросеть под названием GoogleNet. Отличительная особенность этой сети была в том, что она использовала в 12 раз меньше параметров (почувствуйте масштабы: 5 000 000 против 60 000 000) и её архитектура структурно была не похожа на архитектуру AlexNet, в которой было восемь слоёв, причём данная сеть давала более точный результат – 6,67% ошибки против 16,4%16.
Разработчики GoogleNet пытались избежать простого увеличения слоёв нейронной сети, потому что данный шаг привёл бы к значительному увеличению использования памяти и сеть была бы больше склонна к перенасыщению при обучении на небольшом и ограниченном наборе примеров.
Проанализируем приём, на который пошли разработчики компании Google для оптимизации скорости и использования памяти. В нейросети GoogleNet свёртка с размером фильтра 7×7 используется один раз в начале обработки изображения, далее максимальный размер – 5×5. Так как количество параметров при свёртке растёт квадратично с увеличением размерности ядра, нужно стараться заменять одну свёртку на несколько свёрток с меньшим размером фильтра, вместе с этим пропустить промежуточные результаты через ReLU (функция активации, возвращающая 0, если сигнал отрицателен, и само значение сигнала, если нет), чтобы внести дополнительную нелинейность. Например, свёртку с размером фильтра 5×5 можно заменить двумя последовательными операциями с размером ядра 3×3. Такая оптимизация позволяет строить более гибкие и глубокие сети. На хранение промежуточных свёрток тратится память, и использовать их более разумно в слоях, где размер карты признаков небольшой. Поэтому в начале сети GoogleNet вместо трёх свёрток 3×3 используется одна 7×7, чтобы избежать избыточного использования памяти.
Например, свёртку с размером фильтра 5×5 можно заменить двумя последовательными операциями с размером ядра 3×3. Такая оптимизация позволяет строить более гибкие и глубокие сети. На хранение промежуточных свёрток тратится память, и использовать их более разумно в слоях, где размер карты признаков небольшой. Поэтому в начале сети GoogleNet вместо трёх свёрток 3×3 используется одна 7×7, чтобы избежать избыточного использования памяти.
Схему архитектуры сети целиком мы приводить здесь не будем, она слишком громоздка и на ней трудно что-либо разглядеть, кому это будет интересно, могут ознакомиться с ней на официальном ресурсе16. Отличительной особенностью нейросети от компании Google является использование специального модуля – Inception (см. рис. 17). Данный модуль, по своей сути, является небольшой локальной сетью. Идея данного блока состоит в том, что на одну карту признаков накладывается сразу несколько свёрток разного размера, вычисляющихся параллельно. В конце все свёртки объединяются в единый блок. Таким образом, можно из исходной карты признаков извлечь признаки разного размера, увеличив эффективность сети и точность обработки признаков. Однако при использовании данной реализации (см. рис. 17) нужно выполнить колоссальный объём вычислений, между тем, при включении данных модулей друг за другом размерность блока будет только расти. Поэтому разработчики во второй версии добавили свёртки, уменьшающие размерность (см. рис. 18).
Рис. 18. Вторая реализация блока Inception.Жёлтые свёртки размера 1×1 введены для уменьшения глубины блоков, и благодаря им, значительно снижается нагрузка на память. GoogleNet содержит девять таких Inception-модулей и состоит из 22 слоёв.
Из-за большой глубины сети разработчики также столкнулись с проблемой затухания градиента при обучении (см. описание процедуры обучения нейросети: коррекция весов осуществляется в соответствии со значением ошибки, производной функции активации – градиента – и т. д.) и ввели два вспомогательных модуля классификатора (см. рис. 19). Данные модули представляют собой выходную часть малой свёрточной сети и уже частично классифицируют объект по внутренним характеристикам самой сети. При обучении нейронной сети данные модули не дают ошибке, распространяющиейся с конца, сильно уменьшиться, так как вводят в середину сети дополнительную ошибку.
д.) и ввели два вспомогательных модуля классификатора (см. рис. 19). Данные модули представляют собой выходную часть малой свёрточной сети и уже частично классифицируют объект по внутренним характеристикам самой сети. При обучении нейронной сети данные модули не дают ошибке, распространяющиейся с конца, сильно уменьшиться, так как вводят в середину сети дополнительную ошибку.
Ещё один полезный аспект в архитектуре GoogleNet, по мнению разработчиков, состоит в том, что сеть интуитивно правильно обрабатывает изображение: сначала картинка обрабатывается в разных масштабах, а затем результаты агрегируются. Такой подход больше соответствует тому, как подсознательно выполняет анализ окружения человек.
В 2015 году разработчики из Google представили модифицированный модуль Inception v2, в котором свёртка 5×5 была заменена на две свёртки 3×3, по причинам, приведённым выше, вдобавок потери информации в картах признаков при таком действии происходят незначительные, так как соседние ячейки имеют между собой сильную корреляционную связь. Также, если заменить свёртку 3×3 на две последовательные свёртки 3×1 и 1×3, то это будет на 33% эффективнее, чем стандартная свёртка, а две свёртки 2×2 дадут выигрыш лишь в 11%17. Данная архитектура нейросети давала ошибку 5,6%, а потребляла ресурсов в 2,5 раза меньше.
Стоит отметить, что точного алгоритма построения архитектуры нейросети не существует. Разработчики составляют свёрточные нейросети, основываясь на результатах экспериментов и собственном опыте.
Нейронную сеть можно использовать для точной классификации изображений, загруженных в глобальную сеть, либо использовать для сортировки фотографий по определённому признаку в галерее смартфона.
Свёрточная нейронная сеть имеет следующие преимущества: благодаря своей структуре, она позволяет значительно снизить количество весов в сравнении с полносвязанной нейронной сетью, её операции легко поддаются распараллеливанию, что положительно сказывается на скорости обучения и на скорости работы, данная архитектура лидирует в области классификации изображений, занимая первые места на соревновании ImageNet. Из-за того, что для сети более важно наличие признака, а не его место на изображении, она инвариантна к различным сдвигам и поворотам сканируемого изображения.
Из-за того, что для сети более важно наличие признака, а не его место на изображении, она инвариантна к различным сдвигам и поворотам сканируемого изображения.
К недостаткам данной архитектуры можно отнести следующие: состав сети (количество её слоёв, функция активации, размерность свёрток, размерность pooling-слоёв, очередность слоёв и т.п.) необходимо подбирать эмпирически к определённому размеру и виду
изображения; сложность обучения: нейросети с хорошим показателем ошибки должны тренироваться на мощных GPU долгое время; и, наверное, главный недостаток – атаки на данные нейросети. Инженеры Google в 2015 году показали, что к картинке можно подмешать невидимый для человеческого зрения градиент, который приведёт к неправильной классификации.
Зануление — Энциклопедия по машиностроению XXL
Инструкции по технике безопасности должны быть вывешены на видных местах. Правила безопасного обслуживания отдельных агрегатов (ГТУ, пылеуловителей, насосов и др.) должны быть подробно изложены в инструкции по эксплуатации данного агрегата. Рабочее место необходимо содержать в чистоте. Лестницы с перилами всегда должны быть исправными. Все лотки и каналы следует закрывать рифленым железом. Все движущиеся части машин (валы, муфты и др.) должны иметь кожухи или ограждения. Горячие поверхности (газоходы, воздуховоды и др.) должны иметь изоляцию, обеспечивающую температуру поверхности не выше 60° С, а электроаппаратура и машины — защитное заземление или зануление, исправность которого периодически проверяется. Кабели необходимо надежно защищать от случайного механического повреждения. При ремонтных работах для освещения запрещено пользоваться светильниками напряжением выше 12 В. При производстве такелажных работ нельзя работать с такелажным оборудованием (тали, лебедки, домкраты, канаты), грузоподъемность которого неизвестна. Запрещается также пользоваться канатами и тросами с оборванными проволоками, находиться под поднимаемым грузом. [c.248]
[c.248]Для защиты от прикосновения могут быть применены все мероприятия, допущенные энергоснабжающим предприятием, например заземление, зануление, применение защитных схем с контролем тока утечки или аварийного потенциала. Для защиты от случайного прикосновения к [c.216]
При прямом соединении оборудования, имеющего электропривод (например, задвижек с дистанционным управлением), с защищаемым трубопроводом возможно снижение эффективности катодной защиты, если зануление, применяемое для защиты от прикосновения к токоведущим элементам, осуществляется путем заземления через средний провод (провод Мр). Устранить этот недостаток можно [c.249]
Заземление и зануление выполняются в соответствии с указаниями ПУЭ, 335— 380 [12]. [c.473]
Удаление со светильников пыли и промывка абажуров крепление патронов, ниппелей и контактов с частичной заменой проверка наличия занулений и заземлений и исправление обнаруженных дефектов исправление подвесок светильников, кронштейнов и бра, а также кронштейнов местного освещения. [c.251]
Применение зануления» взамен заземления в сетях, в которых нейтраль [c.741]
Категорически запрещается производить работу электроинструментом без его заземления, а в сетях с заземленной нейтралью — без зануления. [c.426]
Заземление (зануление) электроустановок следует применять [c.521]
Защитное заземление или зануление электроустановок согласно Правилам устройства электроустановок [40] следует выполнять [c.430]
Сопротивления заземляющих устройств в системах защитного заземления и зануления не должны превышать значений, приведенных в табл. 11.29 и 11.30. [c.431]
Замыкающие затраты на топливо, электроэнергию, теплоту 39G Зануление 430 [c.447]
Осмотр металлоконструкций крана, его заклепочных или сварных соединений, проверка заземления или зануления электрических кранов, проверка исправности подкрановых путей, а также узлов механизмов, требующих разборки (крюка в нарезной части, осей блоков и др. ), могут быть произведены до очередного освидетельствования.
[c.584]
), могут быть произведены до очередного освидетельствования.
[c.584]
Профилактика травматизма на производстве обеспечивается внедрением техники безопасности, профилактика профессиональных заболеваний — нормализацией условий труда. Безопасность труда должна учитываться уже на стадии проектирования и монтажа оборудования, в расчетах его на прочность и надежность, при выборе его эксплуатационных параметров, технологических процессов и материалов, при механизации тяжелых, трудоемких, опасных и вредных работ, организации рабочих мест. При проектировании предприятий предусматриваются системы улавливания, обезвреживания и утилизации отходов. К мероприятиям по технике безопасности относят также применение предохранительных устройств, приборов, систем (ограждения, блокировки, заземления и зануления, автоматического отключения и др.) установку сигнализации и маркировку оборудования, инструмента и приборов нормирование условий труда (режима труда и отдыха) надзор за ведением работ и др. Комплекс мероприятий по охране труда включает в себя также подготовку персонала (профессиональный, медицинский и психологический отбор, обучение, тренировки, инструктирование) и его обеспечение средствами индивидуальной защиты, а также аварийно-спасательные меры. Под безопасностью труда понимается комплекс организационно-технических мероприятий, направленных на создание безопасных условий труда. Требования к безопасности труда стандартизованы государством и объединены в двух направлениях [c.14]
Наиболее распространенными техническими средствами защиты, используемыми на металлорежущих станках, являются защитное заземление и зануление. [c.19]
Профилактикой травматизма на производстве является соблюдение правил техники безопасности, профилактикой профессиональных заболеваний — нормализация условий труда. К мероприятиям по технике безопасности относят механизацию тяжелых, трудоемких, опасных и вредных работ, правильную организацию рабочих мест, применение предохранительных устройств, приборов, а также систем ограждения, блокировки, заземления и зануления, автоматического отключения и др. [c.432]
[c.432]
III — цепи питания и цепи защитного заземления и зануления (защитная цепь) [c.788]
Обеспечение электробезопасности техническими способами и средствами должно достигаться применением защитного заземления, зануления, защитного отключения, выравнивания потенциала. [c.492]
Для обеспечения работоспособности зануления проводимость нулевых защитных проводников должна быть выбрана такой, чтобы при замыкании на корпус или на нулевой защитный проводник возникал ток КЗ, превышающий не менее чем в 3 раза номинальный ток плавкого элемента ближайшего предохранителя в 3 раза номинальный ток нерегулируемого расцепителя или уставку регулируемого расцепителя автоматического выключателя, имеющего обратно зависимую от тока характеристику. При защите сетей автоматическими выключателями, имеющими только электромагнитный расцепи-тель, проводимость указанных проводников должна обеспечивать ток не ниже уставки тока мгновенного срабатывания, умноженный на коэффициент, учитывающий разброс (по заводским данным), и на коэффициент запаса 1,1. При отсутствии заводских данных для автоматических выключателей с номинальным током до 100 А кратность тока КЗ относительно уставки следует принимать не менее 1,4, а для автоматических выключателей с номинальным током более 100 А — не менее 1,25. [c.494]
Указанные проводники могут служить единственными заземляющими или нулевыми защитными проводниками, если они по проводимости отвечают требованиям к устройству заземления или зануления и если обеспечена непрерывность электрической цепи на всем протяжении использования. [c.494]
Магистрали заземления или зануления и ответвления от них в помещениях и наружных установках должны быть доступны для осмотра. Исключение составляют нулевые жилы и оболочки кабелей, арматура железобетонных конструкций, а также заземляющие и нулевые защитные проводники, проложенные в трубах и коробах непосредственно в теле строительных конструкций. [c.494]
[c.494]
В отношении деформационных свойств элементов структуры композиционных материалов после выполнения условия разрушения авторами научных работ принимаются весьма различные предположения [144,289] зануление всех деформационных характеристик [14] (прямая 1 на рис. 11.1) или только некоторых элементов матрицы жесткостей [109, 226], использование модели типа идеального упругопластического тела [189, 289] (прямая 2) или линейно разупрочняющегося тела [289, 363] (прямая 5). Используются также некоторые комбинированные модели, например, в [144]. Ряд моделей учитывает много-стадийность процесса разрушения структурного элемента [109]. [c.246]
Выполнение сетей заземления и зануления [c.48]
Защитное заземление, зануление, защитное отключение оборудования, приборов, средств сигнализации и блокировки выполняются в соответствии с требованиями стандартов и правил. [c.29]
Строго соблюдать требования ПУЭ ( УП-6-49) и ПТЭ электроустановок потребителей ( ЭП1-2-20) о запрещении использования сетей заземления и зануления в качестве обратных проводов при сварке. [c.159]
Для обеспечения безопасности людей в соответствии с требованиями ПУЭ должно быть выполнено заземление (зануление) металлических частей установок и корпусов электрооборудования, которые вследствие нарушения изоляции могут оказаться под напряжением. [c.170]
К частям, подлежащим заземлению (занулению), относятся [c.170]
Заземлению (занулению) не подлежат [c.170]
В цепи нулевых рабочих проводников, если они одновременно служат для зануления, допускается применение выключателей, которые одновременно с отключением нулевых рабочих проводников отключают также, все провода, находящиеся под напряжением. [c.171]
Продолжительность нескольких одновременных замыканий на зем-ЛЮ должна быть надежно ограничена до минимума. Если заземление какого-либо проводника или какой-либо части установки, относящихся к цепи рабочего тока, необходимо по эксплуатационным соображениям или для предотвращения слишком высоких напряжений прикосновения, то установку следует заземлять только в одном месте. Поэтому в сетях постоянного тока зануление как защитное мероприятие по VDE0100, 10 N [7] не может быть применено.
[c.315]
Если заземление какого-либо проводника или какой-либо части установки, относящихся к цепи рабочего тока, необходимо по эксплуатационным соображениям или для предотвращения слишком высоких напряжений прикосновения, то установку следует заземлять только в одном месте. Поэтому в сетях постоянного тока зануление как защитное мероприятие по VDE0100, 10 N [7] не может быть применено.
[c.315]
Иногда целесообразно для заземления электроустановок систем автоматизации использовать землю источника питания, когда она предусмотрена в качестве разводки между щитами, так как большое сопротивление заземляющих проводников (сечением 0,75—1,5 мм ) может отрицательно влиять на защиту от токов короткого замыкания при соединении обратным занулением проводов с глухозаземленной нейтралью и корпусом электрооборудования при этом полная проводимость заземляющих проводников должна быть не менее 0,5 сечения фазного провода, а при изолированной—не менее 0,33 сечения фазного провода. [c.178]
При пользовании электрическим инструменто.м необходимо проверять наличие заземлений или занулений. Подключать электроинструменты к электрической сети следует через штепсельную розетку. [c.204]
Заземлению (занулению) подлежат корпуса электрических машин, трансформаторов, аппаратов, светильников и т. п. приводы электрических аппаратов вторичные обмотки понижающих трансформаторов каркасы распределительных щитов, щитков, шкафов и т. п. металлоконструкции распре-делителыгых устройств, металлические кабельные конструкции, оболочки муфты, металлические оболочки проводов стальные трубы электропроводок, лотки, короба, тросы и т. п. металлические корпуса передвижных и переносных электроприемников, [c.521]
Зануление — преднамеренное электрическое соединение с нулевым защитным проводником металлических нетоковедущих частей, которые могут оказаться под напряжением. Нулевой защитный проводник — проводник, соединяющий зануляемые части с глухозаземленной нейтральной точкой обмотки источника тока или ее эквивалентом [12]. Зануление применяют только в электроустановках напряжением до 1000 В, питающихся от сети с глухозаземленной нейтралью, в том числе в наиболее распространенных установках 380/220 В.
[c.430]
Зануление применяют только в электроустановках напряжением до 1000 В, питающихся от сети с глухозаземленной нейтралью, в том числе в наиболее распространенных установках 380/220 В.
[c.430]
Защитному заземлению и занулению подлежат корпуса электрических машин, трансформаторов, аппаратов, светильников приводы электрических аппаратов каркасы распределительных устройств и другие металлические нетоковедущие части, которые могут оказаться, под напряжением и к которым может прикоснуться человек. [c.430]
Та блица 11.30. Наибольшие допустимые сопротивления заземляющих устройств в системе зануления (трехфазные четырехпроводные сети напряжением до 1000 В с глухозаземленной нейтралью) [40] [c.431]
Занулением (ГОСТ 12.1.030—81) называется преднамеренное электрическое соединение с нулевым защитным проводником металлических нетоковедущих частей, которые могут оказаться под напряжением. [c.19]
Зануление — преднамеренное электрическое соединение металлических нетоковедущих частей с заземленной нейтральной точкой источника электроэнергии с целью автоматического отключения участка сети при замыкании на корпус [14, 40]. [c.493]
ГОСТ 12.1.030-82. ССБТ. Электробезопасность. Защитное заземление, зануление. [c.508]
ОБ ОБЕСПЕЧЕНИИ ЭЛЕКТРОБЕЗОПАСНОСТИ ПРИ ОДНОФАЗНЫХ КОРОТКИХ ЗАМЫКАНИЯХ В СЕТЯХ НАПРЯЖЕНИЕМ ДО 1000 В С ЗАЗЕМЛЕ1ШОЙ НЕЙТРАЛЬЮ (НАДЕЖНОСТИ СИСТЕМЫ ЗАНУЛЕНИЯ) [c.157]
Указанные недостатки могут быть устранены. Некоторые затруднения возникают при наличии электродвигателей крупной мощности, в частности во взрывоопасных установках, в которых металлическая связь с нейтралью трансформатора (зануление) оказывается часто веэффегшвной и должна сочетаться с защитным отключением. [c.158]
В электроустановках с глухозаземленной нейтралью при замыканиях на заземленные части должно быть обеспечено надежное автоматическое отключение поврежденных участков сети с наименьшим временем отключения. С этой целью обязательна металлическая связь корпусов электрооборудования и металлоконструкций с заземленной нейтралью (зануление).
[c.171]
С этой целью обязательна металлическая связь корпусов электрооборудования и металлоконструкций с заземленной нейтралью (зануление).
[c.171]
Присоединение заземляющих и нулевых защитных проводников к частям оборудования, подлежащим заземлению или зануленню, должно быть выполнено сваркой или болтовым соединением. Присоединение должно быть доступно для осмотра. [c.171]
Item-based коллаборативная фильтрация своими руками
Одной из наиболее популярных техник для построения персонализированных рекомендательных систем (RS, чтобы не путать с ПиСи) является коллаборативная фильтрация. Коллаборативная фильтрация бывает двух типов: user-based и item-based. User-based часто используется в качестве примера построения персонализированных RS [на хабре, в книге Т.Сегаран,…]. Тем не менее, у user-based подхода есть существенный недостаток: с увеличением количества пользователей RS линейно увеличивается сложность вычисления персонализированной рекомендации.
Когда количество объектов для рекомендаций большое, затраты на user-based подход могут быть оправданы. Однако во многих сервисах, в том числе и в ivi.ru, количество объектов в разы меньше количества пользователей. Для таких случаев и придуман item-based подход.
В этой статье я расскажу, как за несколько минут можно создать полноценную персонализированную RS на основе item-based подхода.
Немного теории
Рассмотрим получение k персонализированных рекомендаций (top-k) для некоторого пользователя A. В случае с user-based подходом, для построения рекомендаций находятся так называемые пользователи-соседи (neighbors) пользователя A. Соседи пользователя А — это пользователи, наиболее похожие на него с точки зрения истории просмотров/рейтингов. Количество соседей варьируется в зависимости от реализации и требований к RS, но обычно не превышает 50. Зная предпочтения соседей и историю просмотров пользователя А, RS строит top-k рекомендаций.
 Такой подход предполагает, что пользователю A понравятся те же объекты, что и пользователям-соседям.
Такой подход предполагает, что пользователю A понравятся те же объекты, что и пользователям-соседям.В случае с item-based подходом пользователь A характеризуется объектами objsA, которые он просмотрел или оценил. Для каждого объекта из objsA определяется m объектов-соседей, т.е. находятся m наиболее похожих объектов с точки зрения просмотров/оценок пользователей. При построении RS для фильмов, m принимает значения от 10 до 30. Все объекты-соседи объединяются во множество из которого исключаются объекты, просмотренные или оцененные пользователем A. Из оставшегося множества строится top-k рекомендаций. Таким образом, при item-based подходе в создании рекомендаций участвуют все пользователи, которым понравился тот или иной объект из objsA.
В нашем случае для получения top-k рекомендаций используется простейший вариант алгоритма Deshpande M. и Karypsis G.. Рекомендации строятся на основе рейтингов зарегистрированных пользователей ivi.ru.
Реализация
Описанный ниже код позволяет получать рекомендации по фильмам для некоторого пользователя A по его истории рейтингов. Данные о рейтингах пользователей ivi.ru (за последние 30 дней) и названиях фильмов для удобства были предварительно выкачены в sqlite БД — ivi_rates.db.
RS построена на Python с использованием пакетов: numpy, scipy, scikit-learn. Некоторые участки кода могут показаться «дикими» вследствие оптимизации, для них есть комментарии.
Подготовка матрицы item-user
Item-user матрица является исходной матрицей как для user-based, так и для item-based коллаборативной фильтрации. Строке данной матрицы соответствует объект, в нашем случае фильм. Столбцу соответствует пользователь. В ячейках матрицы расположены рейтинги.
Для уменьшения шума в рекомендациях и увеличения их точности используются только данные о фильмах с количеством просмотров/рейтингов не менее определенного значения (confidence value). В нашем случае в построении item-user матрицы будут участвовать фильмы минимум c 10 рейтингами. Также, для уменьшения размерности пространства пользователей, мы исключим из построения всех пользователей, которые оценили только один фильм.
Также, для уменьшения размерности пространства пользователей, мы исключим из построения всех пользователей, которые оценили только один фильм.
Матрица item-user будет сильно разрежена, поэтому и хранить её мы будем соответствующим образом.
import sqlite3
conn = sqlite3.connect('ivi_rates.db')
cursor = conn.cursor()
# строим индекс user_id -> col_id, где col_id - идентификатор столбца в матрице
# берем пользователей, оценивших не менее 2 фильмов
users_sql = """
SELECT user_id
FROM rates
WHERE rate IS NOT NULL
GROUP BY user_id HAVING count(obj_id) >= 2
"""
cursor.execute(users_sql)
user_to_col = {}
for col_id, (user_id,) in enumerate(cursor):
user_to_col[user_id] = col_id
# строим индекс obj_id -> row_id, где row_id - идентификатор строки в матрице
# берем только фильмы, которые оценили не менее 10 пользователей
objs_sql = """
SELECT obj_id
FROM rates
WHERE rate IS NOT NULL AND user_id IN (
SELECT user_id
FROM rates
WHERE rate IS NOT NULL
GROUP BY user_id HAVING count(obj_id) >= 2
)
GROUP BY obj_id HAVING count(user_id) >= 10
"""
cursor.execute(objs_sql)
obj_to_row = {}
for row_id, (obj_id,) in enumerate(cursor):
obj_to_row[obj_id] = row_id
print u"Количество пользователей:", len(user_to_col)
print u"Количество объектов:", len(obj_to_row)
Количество пользователей: 353898Количество объектов: 7808Индексы нужны для быстрого преобразования идентификаторов пользователей/фильмов в идентификаторы столбцов/строк. Зная количество фильмов и пользователей, можно упростить процесс создания и заполнения матрицы item-user.
from scipy.sparse import lil_matrix
sql = """
SELECT obj_id, user_id, rate
FROM rates
WHERE rate IS NOT NULL
"""
cursor.execute(sql)
matrix = lil_matrix((len(obj_to_row), len(user_to_col))) # создаем матрицу нужных размеров
# заполняем матрицу
for obj_id, user_id, rate in cursor:
row_id = obj_to_row. get(obj_id)
col_id = user_to_col.get(user_id)
if row_id is not None and col_id is not None:
matrix[row_id, col_id] = min(rate, 10)
percent = float(matrix.nnz) / len(obj_to_row) / len(user_to_col) * 100
print u"Процент заполненности матрицы: %.2f%%" % percent
 get(obj_id)
col_id = user_to_col.get(user_id)
if row_id is not None and col_id is not None:
matrix[row_id, col_id] = min(rate, 10)
percent = float(matrix.nnz) / len(obj_to_row) / len(user_to_col) * 100
print u"Процент заполненности матрицы: %.2f%%" % percent
get(obj_id)
col_id = user_to_col.get(user_id)
if row_id is not None and col_id is not None:
matrix[row_id, col_id] = min(rate, 10)
percent = float(matrix.nnz) / len(obj_to_row) / len(user_to_col) * 100
print u"Процент заполненности матрицы: %.2f%%" % percent
Процент заполненности матрицы: 0.17%Подготовка матрицы item-item
Основной матрицей для item-based подхода является матрица item-item. Строкам и столбцам этой матрицы соответствуют объекты. В ячейках хранится значение схожести объектов. Для определения схожести двух объектов используется метрика косинусной меры угла. Список рекомендаций вычисляется путем перемножения матрицы item-item на вектор просмотров/рейтингов пользователя A.
В item-item матрице все значения по диагонали равны 1 (объект на 100% похож на себя). Чтобы исключить диагональ из рекомендаций, ее обычно зануляют.
При стабильном интересе пользователей к объектам, матрица item-item также является стабильной. Под стабильностью интересов подразумевается следующее: если пользователю B нравятся фильмы, понравившиеся пользователю A, то велика вероятность, что пользователю B понравится еще один фильм из списка фильмов, понравившихся пользователю A. Стабильность матрицы означает, что с появлением новых просмотров/рейтингов значения внутри ячеек матрицы будут почти неизменны. Стабильность позволяет не перестраивать матрицу каждый раз при появлении новых рейтингов.
Scipy, numpy, scikit позволяют выполнять матричные операции очень быстро (скорее всего, быстрее, чем любая самописная итерация). При использовании матриц лучше использовать функции из этих пакетов.
from sklearn.preprocessing import normalize
from scipy.sparse import spdiags
# косинусная мера вычисляется как отношение скалярного произведения векторов(числитель)
# к произведению длины векторов(знаменатель)
# нормализуем исходную матрицу
# (данное действие соответствует приведению знаменателя в формуле косинусной меры к 1)
normalized_matrix = normalize(matrix. tocsr()).tocsr()
# вычисляем скалярное произведение
cosine_sim_matrix = normalized_matrix.dot(normalized_matrix.T)
# обнуляем диагональ, чтобы исключить ее из рекомендаций
# быстрое обнуление диагонали
diag = spdiags(-cosine_sim_matrix.diagonal(), [0], *cosine_sim_matrix.shape, format='csr')
cosine_sim_matrix = cosine_sim_matrix + diag
percent = float(cosine_sim_matrix.nnz) / cosine_sim_matrix.shape[0] / cosine_sim_matrix.shape[1] * 100
print u"Процент заполненности матрицы: %.2f%%" % percent
print u"Размер в МБ:", cosine_sim_matrix.data.nbytes / 1024 / 1024
 tocsr()).tocsr()
# вычисляем скалярное произведение
cosine_sim_matrix = normalized_matrix.dot(normalized_matrix.T)
# обнуляем диагональ, чтобы исключить ее из рекомендаций
# быстрое обнуление диагонали
diag = spdiags(-cosine_sim_matrix.diagonal(), [0], *cosine_sim_matrix.shape, format='csr')
cosine_sim_matrix = cosine_sim_matrix + diag
percent = float(cosine_sim_matrix.nnz) / cosine_sim_matrix.shape[0] / cosine_sim_matrix.shape[1] * 100
print u"Процент заполненности матрицы: %.2f%%" % percent
print u"Размер в МБ:", cosine_sim_matrix.data.nbytes / 1024 / 1024
tocsr()).tocsr()
# вычисляем скалярное произведение
cosine_sim_matrix = normalized_matrix.dot(normalized_matrix.T)
# обнуляем диагональ, чтобы исключить ее из рекомендаций
# быстрое обнуление диагонали
diag = spdiags(-cosine_sim_matrix.diagonal(), [0], *cosine_sim_matrix.shape, format='csr')
cosine_sim_matrix = cosine_sim_matrix + diag
percent = float(cosine_sim_matrix.nnz) / cosine_sim_matrix.shape[0] / cosine_sim_matrix.shape[1] * 100
print u"Процент заполненности матрицы: %.2f%%" % percent
print u"Размер в МБ:", cosine_sim_matrix.data.nbytes / 1024 / 1024
Процент заполненности матрицы: 45.54%Размер в МБ: 211На самом деле, в каждой строке полученной матрицы item-item хранится список соседей объекта, соответствующего данной строке. Как уже было сказано ранее, для item-based подхода достаточно хранить m наиболее похожих объектов-соседей (top-m). Так как мы работаем с фильмами, то возьмем m равным 30.
from scipy.sparse import vstack
import numpy as np
cosine_sim_matrix = cosine_sim_matrix.tocsr()
m = 30
# построим top-m матрицу в один поток
rows = []
for row_id in np.unique(cosine_sim_matrix.nonzero()[0]):
row = cosine_sim_matrix[row_id] # исходная строка матрицы
if row.nnz > m:
work_row = row.tolil()
# заменяем все top-m элементов на 0, результат отнимаем от row
# при большом количестве столбцов данная операция работает быстрее,
# чем простое зануление всех элементов кроме top-m
work_row[0, row.nonzero()[1][np.argsort(row.data)[-m:]]] = 0
row = row - work_row.tocsr()
rows.append(row)
topk_matrix = vstack(rows)
# нормализуем матрицу-результат
topk_matrix = normalize(topk_matrix)
percent = float(topk_matrix.nnz) / topk_matrix.shape[0] / topk_matrix.shape[1] * 100
print u"Процент заполненности матрицы: %.2f%%" % percent
print u"Размер в МБ:", topk_matrix.data.nbytes / 1024 / 1024
Процент заполненности матрицы: 0. 38% 38%
38%Размер в МБ: 1Согласно работе Deshpande M. и Karypsis G. рекомендации получаются лучше при нормализации конечной матрицы.
Полученная top-m матрица является сильно разреженой и ее размер составляет всего 1 МБ. Т.е. в нашем случае для построения рекомендаций на основании данных о 353898 пользователях и 7808 объектах достаточно хранить матрицу размером всего 1 МБ.
Получение рекомендаций
Теперь, когда у нас есть матрица item-item, мы можем построить персонализированные рекомендации для пользователя А.
Получение рекомендаций состоит из трех этапов:
- перемножить матрицу item-item и вектор просмотров/рейтингов пользователя A;
- в векторе-результате занулить ячейки, соответствующие фильмам, которые пользователь A уже просмотрел или оценил;
- отсортировать фильмы в порядке убывания значений, оставшихся в ячеках вектора-результата, и получить top-k рекомендованных фильмов.
# индекс для преобразования row_id -> obj_id, где row_id - идентификатор строки в матрице
row_to_obj = {row_id: obj_id for obj_id, row_id in obj_to_row.iteritems()}
# заранее собираем индекс obj_id -> title
title_sql = """
SELECT obj_id, obj_title
FROM rates
GROUP BY obj_id, obj_title
"""
cursor.execute(title_sql)
obj_to_title = {}
for obj_id, title in cursor:
obj_to_title[obj_id] = title
#подготавливаем вектор рейтингов пользователя:
user_vector = lil_matrix((len(obj_to_row), 1))
user_vector[7780, 0] = 7 # Скорый «Москва-Россия»
user_vector[7755, 0] = 10 # Отель «Гранд Будапешт»
user_vector[7746, 0] = 8 # Мстители
user_vector[7657, 0] = 8 # Охотники за сокровищами
user_vector[6683, 0] = 7 # 300 спартанцев: Расцвет империи
user_vector[7656, 0] = 9 # Невероятная жизнь Уолтера Митти
user_vector[7356, 0] = 9 # Одинокий рейнджер
user_vector[7296, 0] = 8 # Елки 3
user_vector[6839, 0] = 7 # Легенда №17
user_vector[4190, 0] = 7 # 21 и больше
user_vector[7507, 0] = 9 # Покорители волн
user_vector[6938, 0] = 9 # Кон-Тики
user_vector[4230, 0] = 10 # Карты, деньги, два ствола
user_vector[3127, 0] = 8 # 13
user_vector = user_vector. tocsr()
 tocsr()
tocsr()
# 1. перемножить матрицу item-item и вектор рейтингов пользователя A
x = topk_matrix.dot(user_vector).tolil()
# 2. занулить ячейки, соответствующие фильмам, которые пользователь A уже оценил
for i, j in zip(*user_vector.nonzero()):
x[i, j] = 0
# превращаем столбец результата в вектор
x = x.T.tocsr()
# 3. отсортировать фильмы в порядке убывания значений и получить top-k рекомендаций (quorum = 10)
quorum = 10
data_ids = np.argsort(x.data)[-quorum:][::-1]
result = []
for arg_id in data_ids:
row_id, p = x.indices[arg_id], x.data[arg_id]
result.append({"obj_id": row_to_obj[row_id], "weight": p})
result
Результат
[{‘obj_id’: 1156180, ‘weight’: 8.4493290509843408},
{‘obj_id’: 978100, ‘weight’: 6.4337821664936943},
{‘obj_id’: 1143770, ‘weight’: 5.5038366682680451},
{‘obj_id’: 978120, ‘weight’: 5.4203284682159421},
{‘obj_id’: 985220, ‘weight’: 5.2386991677359047},
{‘obj_id’: 1033040, ‘weight’: 5.0466735584390117},
{‘obj_id’: 1033290, ‘weight’: 4.8688497271055011},
{‘obj_id’: 1046560, ‘weight’: 4.6880514059004224},
{‘obj_id’: 984040, ‘weight’: 4.6199406111214927},
{‘obj_id’: 960770, ‘weight’: 4.5788899365020477}]
Ура! Мы построили рекомендации для пользователя. Однако в таком виде они мало о чем говорят. Хорошо, когда RS объясняет пользователю, почему ему рекомендуют тот или иной объект. Существует множество способов объяснения рекомендаций, полученных с использованием коллаборативной фильтрации (подробнее можно почитать у J.Herlocker, J.Konstan, J.Riedl). Здесь приведен один из способов объяснения рекомендаций, который легко реализуется с учетом имеющихся матриц и данных.
Каждый рекомендованный фильм будет объясняться так: Мы рекомендуем Вам "%(title)s", так как он нравится пользователям, просмотревшим "%(impact)s". Вы оценили "%(impact)s" на %(impact_value)s.
# фильмы, которые мы рекомендуем, и их связь с фильмами, которые оценил пользователь
result = []
for arg_id in data_ids:
row_id, p = x. indices[arg_id], x.data[arg_id]
obj_id = row_to_obj[row_id]
# определяем, как повлиял на рекомендуемый фильм каждый из оцененных пользователем фильмов.
# topk_matrix[row_id] - вектор соседей рекомендованного фильма obj_id
# .multiply(user_vector.T) - зануляет все фильмы, которые пользователь не оценивал
# impact_vector - вес просмотренных пользователем фильмов при подсчете метрики рекомендации obj_id
impact_vector = topk_matrix[row_id].multiply(user_vector.T)
# наиболее значимый фильм - ячейка с наибольшим значением в impact_vector
impacted_arg_id = np.argsort(impact_vector.data)[-1]
impacted_row_id = impact_vector.indices[impacted_arg_id]
impact_value = user_vector[impacted_row_id, 0]
impacted_obj_id = row_to_obj[impacted_row_id] # наиболее значимый фильм
rec_item = {
"title": obj_to_title[obj_id],
"weight": p,
"impact": obj_to_title[impacted_obj_id],
"impact_value": impact_value
}
result.append(rec_item)
print u'''Мы рекомендуем Вам "%(title)s", так как он нравится пользователям, просмотревшим "%(impact)s". Вы оценили "%(impact)s" на %(impact_value)s.''' % rec_item
 indices[arg_id], x.data[arg_id]
obj_id = row_to_obj[row_id]
# определяем, как повлиял на рекомендуемый фильм каждый из оцененных пользователем фильмов.
# topk_matrix[row_id] - вектор соседей рекомендованного фильма obj_id
# .multiply(user_vector.T) - зануляет все фильмы, которые пользователь не оценивал
# impact_vector - вес просмотренных пользователем фильмов при подсчете метрики рекомендации obj_id
impact_vector = topk_matrix[row_id].multiply(user_vector.T)
# наиболее значимый фильм - ячейка с наибольшим значением в impact_vector
impacted_arg_id = np.argsort(impact_vector.data)[-1]
impacted_row_id = impact_vector.indices[impacted_arg_id]
impact_value = user_vector[impacted_row_id, 0]
impacted_obj_id = row_to_obj[impacted_row_id] # наиболее значимый фильм
rec_item = {
"title": obj_to_title[obj_id],
"weight": p,
"impact": obj_to_title[impacted_obj_id],
"impact_value": impact_value
}
result.append(rec_item)
print u'''Мы рекомендуем Вам "%(title)s", так как он нравится пользователям, просмотревшим "%(impact)s". Вы оценили "%(impact)s" на %(impact_value)s.''' % rec_item
indices[arg_id], x.data[arg_id]
obj_id = row_to_obj[row_id]
# определяем, как повлиял на рекомендуемый фильм каждый из оцененных пользователем фильмов.
# topk_matrix[row_id] - вектор соседей рекомендованного фильма obj_id
# .multiply(user_vector.T) - зануляет все фильмы, которые пользователь не оценивал
# impact_vector - вес просмотренных пользователем фильмов при подсчете метрики рекомендации obj_id
impact_vector = topk_matrix[row_id].multiply(user_vector.T)
# наиболее значимый фильм - ячейка с наибольшим значением в impact_vector
impacted_arg_id = np.argsort(impact_vector.data)[-1]
impacted_row_id = impact_vector.indices[impacted_arg_id]
impact_value = user_vector[impacted_row_id, 0]
impacted_obj_id = row_to_obj[impacted_row_id] # наиболее значимый фильм
rec_item = {
"title": obj_to_title[obj_id],
"weight": p,
"impact": obj_to_title[impacted_obj_id],
"impact_value": impact_value
}
result.append(rec_item)
print u'''Мы рекомендуем Вам "%(title)s", так как он нравится пользователям, просмотревшим "%(impact)s". Вы оценили "%(impact)s" на %(impact_value)s.''' % rec_item
Результат
Мы рекомендуем Вам «Кухня в Париже», так как он нравится пользователям, просмотревшим «Скорый «Москва-Россия»».
Вы оценили «Скорый «Москва-Россия»» на 7.0.
**************************
Мы рекомендуем Вам «Невозможное», так как он нравится пользователям, просмотревшим «Кон-Тики».
Вы оценили «Кон-Тики» на 9.0.
**************************
Мы рекомендуем Вам «Приключения мистера Пибоди и Шермана», так как он нравится пользователям, просмотревшим «Скорый «Москва-Россия»».
Вы оценили «Скорый «Москва-Россия»» на 7.0.
**************************
Мы рекомендуем Вам «Паркер», так как он нравится пользователям, просмотревшим «Карты, деньги, два ствола».
Вы оценили «Карты, деньги, два ствола» на 10. 0.
0.
**************************
Мы рекомендуем Вам «Бойфренд из будущего», так как он нравится пользователям, просмотревшим «Одинокий рейнджер».
Вы оценили «Одинокий рейнджер» на 9.0.
**************************
Мы рекомендуем Вам «Волк с Уолл-стрит», так как он нравится пользователям, просмотревшим «Невероятная жизнь Уолтера Митти».
Вы оценили «Невероятная жизнь Уолтера Митти» на 9.0.
**************************
Мы рекомендуем Вам «Горько!», так как он нравится пользователям, просмотревшим «Елки 3».
Вы оценили «Елки 3» на 8.0.
**************************
Мы рекомендуем Вам «Стив Джобс. Потерянное интервью», так как он нравится пользователям, просмотревшим «Кон-Тики».
Вы оценили «Кон-Тики» на 9.0.
**************************
Мы рекомендуем Вам «Техасская резня бензопилой 3D», так как он нравится пользователям, просмотревшим «Отель «Гранд Будапешт»».
Вы оценили «Отель «Гранд Будапешт»» на 10.0.
**************************
Мы рекомендуем Вам «Хоббит: Пустошь Смауга», так как он нравится пользователям, просмотревшим «Невероятная жизнь Уолтера Митти».
Вы оценили «Невероятная жизнь Уолтера Митти» на 9.0.
**************************
В приведенном примере построения RS не используется нормализация рейтингов, так как тема нормализации данных достойна отдельной статьи.
Описанный способ построения персонализированной RS позволяет показать, что item-based подход является мощным инструментом для построения RS. В то же время, стоит понимать, что современные RS используют несколько персонализированных и неперсонализированных методов для построения рекомендаций. Комбинированное использование различных методов позволяет создавать хорошие рекомендации независимо от количества данных о пользователе или объекте.
Определение нулевой матрицы
Нулевая матрица
Что такое нулевая матрица?
Вспомните из нашего урока по записи матриц, что матрица — это упорядоченный список чисел, заключенный в прямоугольную скобку. Для нулевой матрицы все упрощается, поскольку вам действительно не нужно беспокоиться о числах, содержащихся в прямоугольном массиве этой нотации, как и говорит название, есть только одно число, которое может содержаться внутри этих матриц, поскольку все его записи.
Для нулевой матрицы все упрощается, поскольку вам действительно не нужно беспокоиться о числах, содержащихся в прямоугольном массиве этой нотации, как и говорит название, есть только одно число, которое может содержаться внутри этих матриц, поскольку все его записи.
Таким образом, нулевая матрица — это матрица любых размеров, в которой все элементы элементов равны нулю.С математической точки зрения нулевую матрицу можно представить выражением:
Уравнение 1: Математическое выражение для нулевой матрицы размеров mxnГде m представляет количество строк, а n количество столбцов, содержащихся в матрице. Следовательно, если мы хотим записать нулевые матрицы разных размеров, нам просто нужно определить m и n в каждом случае и заполнить все записи внутри скобок матриц нулями.
Примеры нулевых матриц можно увидеть ниже:
Уравнение 2: Примеры нулевых матриц различных размеровИз приведенных выше примеров нотации нулевой матрицы обратите внимание, что эти матрицы могут иметь любой размер и комбинацию измерений, и они не обязательно являются квадратными матрицами.Таким образом, вы можете иметь нулевую матрицу с любым количеством строк или столбцов, но помните, что для любого заданного размера можно получить только одну нулевую матрицу (что имеет смысл, поскольку есть только один способ иметь все нули в качестве записей в матрица определенного размера или размерной комбинации).
Не путайте нулевую матрицу с тем, что люди могут назвать «нулевой диагональной матрицей». Такая нулевая диагональная матрица обычно относится к полой матрице, где все диагональные элементы внутри нее равны нулю, а остальные ее элементы могут быть любым числом.Сходство между обычной нулевой матрицей и пустой матрицей происходит от их следа (сложения элементов на их диагоналях), поскольку у обоих есть все нулевые элементы, которые нужно добавить, чтобы получить след, равный нулю. Таким образом, оба этих типа матриц представляют собой то, что мы называем матрицей нулевого следа.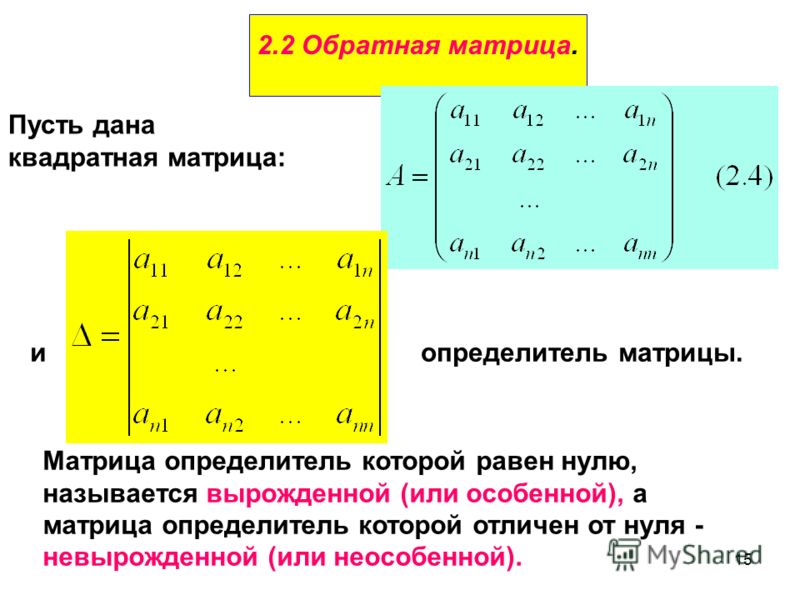
Важные примечания о нулевой матрице
После того, как мы изучили определение нулевой матрицы, давайте поговорим о некоторых особых характеристиках этой матрицы.
- Каков ранг нулевой матрицы?
Помните, что ранг матрицы соответствует максимальному количеству линейно независимых столбцов внутри матрицы. Мы можем определить ранг матрицы, вычислив ее форму эшелона строк, а затем подсчитав левые ненулевые строки, цель которых состоит в том, чтобы найти размерность векторного пространства для рассматриваемой матрицы.
Итак, если мы говорим о разрешимой системе линейных уравнений, преобразованной в матричную запись, определение ранга такой матрицы позволяет нам увидеть максимальное количество независимых переменных и, таким образом, размерные плоскости, для которых система может быть представлена графически.
Как же тогда получить это для нулевой матрицы? Для этого нам сначала нужно спросить себя, являются ли векторы внутри нулевой матрицы линейно независимыми друг от друга? Не совсем, все они одинаковые и все нулевые векторы. Так случилось ли, что они представляют собой какую-либо плоскость измерения? Нет. Можете ли вы на самом деле свести его к форме эшелона строк? Нет. Таким образом, если задуматься, нулевая матрица содержит нулевое количество линейно независимых столбцов и нулевое количество ненулевых строк, и поэтому наш окончательный вывод состоит в том, что ранг нулевой матрицы должен быть равен нулю.
Если вы подумаете об этой идее более глубоко, вы поймете, что любая ненулевая матрица не может иметь ранг меньше единицы, другими словами, чтобы любая матрица имела ранг нуля, она должна содержать все нулевые элементы внутри, Итак, мы пришли к выводу, что только нулевые матрицы имеют нулевой ранг. - Обратима ли нулевая матрица?
Для практических целей мы оставим полное объяснение того, как узнать, является ли матрица обратимой или нет, и как инвертировать те, которые для наших следующих уроков будут говорить об обратимой матрице 2×2. А пока прямо скажем, что нулевая матрица необратима.
Есть несколько правил, которые могут это доказать, например, его определитель равен нулю, а если матрица квадратная, то ее ранг меньше, чем ее размерность. Опять же, мы поговорим об этом немного больше в наших следующих уроках об инвертировании матриц. Но давайте задумаемся над этой идеей на минуту: если мы упомянули ранее, что для любой матрицы определенного размера или размеров существует только одна конфигурация, в которой все ее элементы равны нулю, поэтому не может быть другого способа, которым вы можете переставить нули, чтобы получить обратную матрицу тех же размеров.Если все записи одинаковы, матрица будет точно такой же, нет «обратного» или «противоположного» от этого. - Можно ли диагонализовать нулевую матрицу?
Мы все еще немного далеки от нашего урока по диагонализации, но пока мы можем сказать, что да, нулевая матрица диагонализуема, поскольку ее нулевые элементы могут легко содержать линейно независимые собственные векторы. Подробнее о диагонализации в последующих уроках.
 А пока прямо скажем, что нулевая матрица необратима.
А пока прямо скажем, что нулевая матрица необратима. Пустое пространство нулевой матрицы
Поскольку нулевая матрица — это небольшая и конкретная концепция, которую можно использовать во многих наших уроках линейной алгебры, теперь мы вынуждены еще раз вернуться к теме более позднего урока: нулевое пространство матрицы.
Давайте еще раз упростим и скажем, что для того, чтобы вектор был частью нулевого пространства матрицы, умножение такой матрицы на упомянутый вектор должно приводить к нулевому вектору, таким образом давая «нулевой» результат.Если рассматриваемая матрица представляет собой матрицу с именем A, которая умножается на вектор u, мы говорим, что u находится в нулевом пространстве A, если выполняется следующее условие:
Уравнение 3: Условие для того, чтобы вектор u был частью нулевого пространства A
Если мы возьмем то, что мы знаем из наших уроков о представлении линейной системы в виде матрицы и матричного уравнения Ax = b, мы можем заметить, что при таком умножении умножаемый вектор фактически представляет собой набор решений, заданных однородной системой.
Ну, любая нулевая матрица, умноженная на вектор, будет иметь в результате нулевой вектор. То есть, если размеры матрицы и вектора соответствуют правилам умножения матриц, другими словами, если умножение может быть определено, то результатом обязательно будет нулевой вектор.
Причина этого в том, что, учитывая, что нулевая матрица содержит только нулевые элементы, любая запись, умноженная на любой элемент в векторе, приведет к нулевому компоненту, который будет частью результирующего вектора.Итак, условие для нулевого пространства выполнено, и это подводит нас к чему-то важному, о котором мы до сих пор не упоминали: нулевая матрица — это то, что мы называем нулевой матрицей, и это можно ясно увидеть, следуя процессу, описанному выше, поскольку нет независимо от того, какой вектор умножается на него, результат всегда будет содержать только нулевые элементы.
Сложение, вычитание и скалярное умножение нулевой матрицы
В этом разделе мы сосредоточимся на демонстрации примеров операций либо с нулевыми матрицами внутри, над которыми работают, либо с проблемами, приводящими к решениям с нулевыми матрицами.Для этого давайте сразу перейдем к примерам упражнений:
Пример 1
Начнем с добавления, содержащего нулевую матрицу. Это довольно простая операция, поэтому давайте начнем с добавления следующего вида:
Уравнение 4: сложение с нулевой матрицей Чтобы решить эту проблему, мы просто добавляем все соответствующие элементы в обе матрицы, чтобы получить результирующую матрицу (которая имеет те же размеры, что и те, из которых она была получена). Итак, результат выглядит так: Уравнение 5: Решение сложения с нулевой матрицей Этот первый пример задачи показывает нам важное свойство нулевой матрицы: когда нулевая матрица либо добавляется, либо вычитается из другой матрицы с такими же размерами, эта матрица остается неизменной и равна результату операции.Пример 2
Чтобы продолжить наш следующий пример, мы работаем над вычитанием матриц, где нулевая матрица вычитается из другой матрицы равного размера.
 Уравнение 6: вычитание с нулевой матрицей
Операция следует тем же принципам, что и сложение в примере 1. Таким образом, решая эту операцию, мы получаем: Уравнение 7: Решение вычитания с нулевой матрицей
Как мы упоминали в нашем уроке о сложении и вычитании матриц, хотя сложение матриц является коммутативным (вы можете изменить порядок матриц, и результат не изменится), вычитания матриц нет, и это хорошо видно на этом примере.
Уравнение 6: вычитание с нулевой матрицей
Операция следует тем же принципам, что и сложение в примере 1. Таким образом, решая эту операцию, мы получаем: Уравнение 7: Решение вычитания с нулевой матрицей
Как мы упоминали в нашем уроке о сложении и вычитании матриц, хотя сложение матриц является коммутативным (вы можете изменить порядок матриц, и результат не изменится), вычитания матриц нет, и это хорошо видно на этом примере.Если бы у вас была нулевая матрица справа от знака минус в уравнении 6, то результат был бы равен другой матрице, участвующей в операции. Но поскольку нулевая матрица была первой, результат операции оказывается отрицательным по сравнению с ненулевой матрицей.
Пример 3
В этом примере мы добавляем следующие две следующие матрицы: Уравнение 8: сложение противоположных матриц Заметили что-то особенное из приведенных выше матриц? Они представляют собой отрицательные матрицы друг друга, или, другими словами, если вы возьмете первую матрицу и умножите ее на отрицательную, вы получите вторую матрицу.Следовательно, эта конкретная операция эквивалентна вычитанию матрицы из самой себя. Чтобы показать это, давайте определим первую матрицу как A: Уравнение 9: Матрица A Затем мы записываем эквивалентную операцию, которую мы объяснили минуту назад: Уравнение 10: Преобразование сложения матриц в вычитание Обратите внимание, что скалярное умножение минус один на A было упрощено, чтобы просто записать его как вычитание двух матриц, которые к настоящему времени обе являются A, и поэтому то, что мы имеем в уравнении 10, можно просто записать как: A — A что, очевидно, имеет нулевой результат.Но поскольку здесь речь идет не только о числах, а о матрицах, нулевой результат должен быть массивом тех же размеров, что и A, и поэтому: Уравнение 11: вычитание самой матрицы Обратите внимание, что субиндексы в правой части уравнения обозначают размеры нулевой матрицы, что означает, что результирующая нулевая матрица должна иметь «m из A» (такое же количество строк, что и A) и «N из A».
 «(такое же количество столбцов, как у A).
Давайте получим результат двумя разными способами: добавлением исходной матрицы, показанным в уравнении 8, и вычитанием матрицы, найденным в конце уравнения 10, чтобы показать, как мы получим тот же результат: нулевую матрицу, чтобы доказать уравнение 11.Уравнение 12: Окончательное решение, полученное двумя разными способами
Вывод из этой проблемы состоит в том, что всякий раз, когда вы вычитаете матрицу из самой себя, вы получаете нулевую матрицу с теми же размерами, что и ваши исходные матрицы. Пример 4
«(такое же количество столбцов, как у A).
Давайте получим результат двумя разными способами: добавлением исходной матрицы, показанным в уравнении 8, и вычитанием матрицы, найденным в конце уравнения 10, чтобы показать, как мы получим тот же результат: нулевую матрицу, чтобы доказать уравнение 11.Уравнение 12: Окончательное решение, полученное двумя разными способами
Вывод из этой проблемы состоит в том, что всякий раз, когда вы вычитаете матрицу из самой себя, вы получаете нулевую матрицу с теми же размерами, что и ваши исходные матрицы. Пример 4 В этом примере мы увидим вычитание двух равных матриц, которые оказываются векторами-столбцами. Уравнение 13: вычитание двух равных векторов-столбцов Здесь снова используется принцип, объясненный в предыдущем упражнении: при вычитании двух равных матриц (которые в данном случае оказываются двумя векторами-столбцами, поскольку каждая из матриц состоит только из одного столбца), результатом является нулевая матрица того же размера. как оригинальные: Уравнение 14: Решение вычитания двух равных векторов-столбцов Пример 5
Вычислите следующее скалярное умножение матрицы: Уравнение 15: Скалярное умножение матрицы на ноль В этом конкретном случае должно быть ясно, что результат будет равен нулю, поскольку все, что вы умножаете на ноль, приведет к нулю.Интересная часть здесь исходит из того факта, что вы умножаете матрицу, и поэтому каждый элемент будет умножен на скаляр снаружи, в данном случае ноль, и что произойдет, вместо того, чтобы получить просто ноль в результате, это умножение даст матрицу, в которой все ее элементы равны нулю, и, таким образом, результатом будет нулевая матрица: Уравнение 16: Результат скалярного умножения матрицы на ноль Что также можно записать как: Уравнение 17: нулевая матрица с размерами 3 x 2 Пример 6
Вычислить следующее скалярное умножение, содержащее нулевую матрицу Уравнение 18: Скалярное умножение нулевой матрицы Как и в случае с прошлыми проблемами, мы можем интуитивно записать ответ в виде нулевой матрицы, поскольку каждый элемент в матрице равен нулю, не имеет значения, умножаете ли вы на них любой другой скаляр, результат всегда будет равен нулю в каждом дело.
 Чтобы расширить операцию, вот как это происходит: Уравнение 19: Результат скалярного умножения нулевой матрицы Пример 7
Чтобы расширить операцию, вот как это происходит: Уравнение 19: Результат скалярного умножения нулевой матрицы Пример 7 Давайте изменим режим наших задач, теперь вам предоставлены матрицы, показанные ниже: Уравнение 20: матрицы B и 0 Имея это в виду, верны ли следующие матричные уравнения? Если нет, поправьте их.
- B + 0 = B
Этот случай соответствует тому, что мы видели в примере 1: наличие двух матриц с одинаковыми размерами, одна из них нулевая матрица, а другая ненулевая матрица, когда вы складываете их вместе, результат равна ненулевой матрице, поскольку нулевая матрица ничего не вносит при добавлении каждого соответствующего элемента в две матрицы, участвующие в операции.Следовательно, это выражение ПРАВИЛЬНО. - 0 — B = B
В этом случае мы можем взглянуть на пример 2 и понять, что это выражение НЕПРАВИЛЬНО. При вычитании матрицы из нулевой матрицы той же размерности результат равен отрицательному значению ненулевой матрицы.
Следовательно, правильным выражением будет 0 — B = -B - B — B = 0
Это выражение ПРАВИЛЬНО и соответствует тому, что мы видели в примерах 3 и 4: если вы вычтете матрицу сама по себе, это приведет к записи путем вычитания записи самого числа, и, таким образом, получится матрица в котором все его входные элементы будут равны нулю (нулевая матрица 0). - 0 + 0 = B
Вышеприведенное выражение НЕПРАВИЛЬНО. При добавлении нуля плюс ноль результат всегда равен нулю. Это случай для каждого элемента результирующей матрицы при добавлении нулевой матрицы и другой равной нулевой матрицы, результатом будет равная нулевая матрица. Таким образом, правильное выражение: 0 + 0 = 0. - 0 ⋅ \ cdot⋅ B = 0
Это выражение ПРАВИЛЬНО. Результатом умножения каждого элемента на элемент в результате этой операции будет ноль, в результате чего получится матрица с нулевыми элементами, то есть нулевая матрица 0. - B ⋅ \ cdot⋅ 0 = 0
Как и в случае e), это выражение ПРАВИЛЬНО, поскольку каждый соответствующий элемент из ненулевой матрицы будет умножен на ноль из нулевой матрицы.

Как упоминалось ранее, нулевая матрица — это очень конкретная концепция, поэтому на этом уроке действительно особо нечего сказать о ней, но это не значит, что она не будет использоваться во многих областях линейной алгебры. Так же, как число ноль в математике, нулевая матрица предоставляет нам представление нулевого пространства, которое мы все еще можем охарактеризовать, другими словами, она может содержать нулевые элементы, но ее качества остаются там, чтобы использовать их по нашему усмотрению с другими матрицами.
В завершение нашего урока мы просто предоставим две дополнительные ссылки на случай, если вы захотите посетить их и посмотреть, как они определяют нулевую матрицу, и предоставим простой пример добавления с нулевой матрицей.На сегодня все, до встречи на следующем уроке!
Нулевая матрица — обзор
5.2 Статистический вывод для RSS
Предположим, что общее количество n единиц должно быть измерено из базовой совокупности по интересующей переменной. Пусть n наборов единиц, каждый размером k, случайным образом выбирается из совокупности с использованием метода простой случайной выборки (SRS). Единицы каждого набора ранжируются любым способом, кроме фактического количественного определения переменной. Наконец, по переменной измеряется одна единица в каждом упорядоченном наборе с заранее заданным рангом.Пусть mr будет количеством измерений на блоках ранга r, r = 1,…, k, таких, что n = ∑r = 1kmr. Пусть X (r) j обозначает измерение на j-й единице измерения с рангом r. Это приводит к URSS размера n из основной популяции как {X (r) j; r = 1,…, k, j = 1,…, mr}. Когда mr = m, r = 1,…, k, URSS сводится к сбалансированному RSS. Стоит отметить, что в схемах выборки ранжированных наборов X (1) j,…, X (k) j являются статистикой независимого порядка (поскольку они получены из независимых наборов), и каждый X (r) j предоставляет информацию о различных слой населения. Структуру URSS можно представить следующим образом:
Структуру URSS можно представить следующим образом:
Xr = {X (r) 1, X (r) 2,…, X (r) mr} ~ iidF (r), r = 1,…, k1,
где F (r) — функция распределения (df) статистики r-го порядка. Второй образец может быть создан с использованием той же процедуры. Мы предполагаем, что вторая выборка сгенерирована с использованием k2, которое может отличаться от k = k1
Yr = {Y (r) 1, Y (r) 2,…, Y (r) mr} ~ iidG (r), r = 1,…, к2.
Интересно проверить H0: F (x) = dG (x − Δ). В частности, нас интересует нулевая гипотеза H0: μx = μy + Δ по сравнению с H0: μx ≠ μy + Δ.Обычно используются два выборочных теста, чтобы определить, происходят ли образцы из одного и того же неизвестного распределения. В нашей настройке мы предполагаем, что X и Y собраны с разными размерами рангов. Следовательно, даже при одних и тех же родительских распределениях дисперсия оценки не будет одинаковой.
Следующее предложение может быть использовано для установления асимптотической нормальности статистики при нулевой гипотезе.
Предложение 1
Пусть F обозначает cdf члена семейства с ∫x2dF (x) <∞ и Fˆ (r) — эмпирическая функция распределения (edf) r-й строки. .Если ϑi = (X¯ (i) −μ (i)) , то (ϑ1,…, ϑk) сходится по распределению к многомерному нормальному распределению с нулевым средним вектором и ковариационной матрицей diag (σ (1) 2 / m1,…, σ (k) 2 / mk) , где σ (i) 2 = ∫ (x − μ (i)) 2dF (i) (x) и μ (i) = ∫xdF ( i) (x).
Предложение 1 предлагает следующую статистику для тестирования H0: µ = µ0,
Z = 1k∑r = 1kX¯ (r) −µ0σˆ → dN (0,1),
где σˆ2 — оценка плагина для V (1k∑r = 1kX¯ (r)),
σˆ2 = 1k2∑r = 1kσˆ (r) 2mr,
и σ (r) 2 — оценка V (X¯ (r)).Используя центральную предельную теорему, получаем доверительный интервал, где
P (μ∈ (X¯ + tα / 2, n − 1σn, X¯ + t1 − α / 2, n − 1σn)) ≈1 − α.
Для оценки дисперсии среднего требуется σ (r) 2. Следовательно, необходимо, чтобы mr≥2. Оценка дисперсии для небольших размеров выборки была бы очень неточной, из чего можно было бы предположить, что основная статистика может быть ненадежной. В разделе 5.4 мы покажем, что параметрическая статистика очень консервативна. Bootstrap предоставляет непараметрическую альтернативу для оценки дисперсии.Метод начальной загрузки может использоваться для получения выборочного распределения интересующей статистики и позволяет оценить стандартную ошибку любого четко определенного функционала. Следовательно, бутстрап позволяет нам делать выводы, когда точное или асимптотическое распределение интересующей статистики недоступно. Процедура генерации повторной выборки для вычисления дисперсии обсуждается в разделе 5.3.
Следовательно, необходимо, чтобы mr≥2. Оценка дисперсии для небольших размеров выборки была бы очень неточной, из чего можно было бы предположить, что основная статистика может быть ненадежной. В разделе 5.4 мы покажем, что параметрическая статистика очень консервативна. Bootstrap предоставляет непараметрическую альтернативу для оценки дисперсии.Метод начальной загрузки может использоваться для получения выборочного распределения интересующей статистики и позволяет оценить стандартную ошибку любого четко определенного функционала. Следовательно, бутстрап позволяет нам делать выводы, когда точное или асимптотическое распределение интересующей статистики недоступно. Процедура генерации повторной выборки для вычисления дисперсии обсуждается в разделе 5.3.
Утверждение 1 можно использовать для получения тестовой статистики для двух выборок {X1,…, Xk1} и {Y1,…, Yk2}.Можно показать, что
T (X, Y) = (1k1∑r = 1k1X¯ (r) −1k2∑r = 1k2Y¯ (r)) — (μ1 − μ2) σˆ → dN (0,1),
, где
σˆ2 = 1k12∑r1 = 1k1σˆ (r1) 2mr1 + 1k22∑r2 = 1k2σˆ (r2) 2mr2.
Мы можем рассмотреть параметрический статистический вывод для асимметричного распределения: пусть X1,…, Xn равны i.i.d. случайная величина со средним значением μ и конечной дисперсией σ2. Поскольку характеристическая функция Sn сходится к e − t2 / 2, характеристическая функция стандартной нормали nSn = n (μ − μ) / σ асимптотически нормально распределена с нулевым средним и единичной дисперсией.Чтобы учесть асимметрию выборки, следующее предложение получает разложение Эджворта для nSn.
Предложение 2
Если EYi6 <∞ и условие Крамера выполняется, асимптотическая функция распределения nSn равна
P (nSn≤x) = Φ (x) + 1nγ (ax2 + b) ϕ (x) + O (n − 1),
где a и b — известные константы, γ — оцениваемая константа, а Φ и ϕ обозначают стандартное нормальное распределение и функции плотности соответственно.Холл (1992) предложил две функции:
S1 (t) = t + aγˆt2 + 13a2γˆ2t3 + n − 1bγˆ, S2 (t) = (2an − 12γˆ) −1 {exp (2an − 12γˆt) −1} + n − 1bγˆ,
, где a = 1/3 и b = 1/6. Чжоу и Динь (2005) предложили
Чжоу и Динь (2005) предложили
S3 (t) = t + t2 + 13t3 + n − 1bγˆ.
Используя Si (t), для i = 1,2,3, можно построить новые доверительные интервалы для μ как
(μˆ − Si (n − 1 / 2t1 − α / 2, n − 1) σˆ, μˆ− Si (n − 1 / 2tα / 2, n − 1) σˆ),
где t1 − α / 2, n − 1 — квартиль 1 − α / 2 распределения t. Однако использование асимптотического распределения выборки делает вывод менее надежным, особенно для параметрических методов. Например, асимптотическое распределение критерия вариации зависит от асимметрии.Этот параметр делает вывод о коэффициенте вариации неточным, см. Amiri (2016). Представляет интерес изучить эту проблему, используя полностью непараметрический подход через бутстрап.
Точные собственные значения и точные нулевые блоки Жордана полностью неотрицательных матриц
Anderson, E., Bai, Z., Bischof, C., Blackford, S., Demmel, J., Dongarra, J., Du Croz , Дж., Гринбаум, А., Хаммарлинг, С., МакКенни, А., Соренсен, Д.: Руководство пользователя LAPACK. Программное обеспечение Environ. Инструменты 9, 3-е изд.СИАМ, Филадельфия (1999)
Google ученый
Андо, Т .: Полностью положительные матрицы. Линейная алгебра Appl. 90 , 165–219 (1987)
MathSciNet Статья МАТЕМАТИКА Google ученый
Крайер, К .: Некоторые свойства полностью положительных матриц. Линейная алгебра Appl. 15 , 1–25 (1976)
MathSciNet Статья МАТЕМАТИКА Google ученый
Деммель, Дж .: Точные сингулярные разложения структурированных матриц. SIAM J. Matrix Anal. Прил. 21 (2), 562–580 (1999)
MathSciNet Статья МАТЕМАТИКА Google ученый
Деммель, Дж., Кахан, В .: Точные сингулярные значения двухдиагональных матриц. SIAM J. Sci. Стат. Comput. 11 (5), 873–912 (1990)
MathSciNet Статья МАТЕМАТИКА Google ученый
Фаллат С.М .: Двдиагональные факторизации полностью неотрицательных матриц. Являюсь. Математика. Пн. 108 (8), 697–712 (2001)
MathSciNet Статья МАТЕМАТИКА Google ученый
Фаллат С.М., Гехтман М.И. Жордановы структуры полностью неотрицательных матриц. Может. J. Math. 57 (1), 82–98 (2005)
MathSciNet Статья МАТЕМАТИКА Google ученый
Фаллат, С.М., Джонсон, К.Р .: Полностью неотрицательные матрицы. Принстонская серия по прикладной математике. Princeton University Press, Princeton (2011)
Google ученый
Гаска М., Пенья Дж. М.: Полная позитивность и устранение Невилла. Линейная алгебра Appl. 165 , 25–44 (1992)
MathSciNet Статья МАТЕМАТИКА Google ученый
Карлин, С.: Полная позитивность, т. I. Stanford University Press, Stanford (1968)
Google ученый
Коев, П .: http://www.math.sjsu.edu/~koev. По состоянию на 7 января 2019 г.
Коев, П .: Точные собственные значения и SVD полностью неотрицательных матриц. SIAM J. Matrix Anal. Прил. 27 (1), 1–23 (2005)
MathSciNet Статья МАТЕМАТИКА Google ученый
Коев П .: Точные вычисления с полностью неотрицательными матрицами. SIAM J. Matrix Anal. Прил. 29 , 731–751 (2007)
MathSciNet Статья МАТЕМАТИКА Google ученый
The MathWorks Inc: Справочное руководство по MATLAB. MathWorks Inc, Натик (1992)
Google ученый
Уитни А.М .: Теорема редукции для вполне положительных матриц.J. Anal. Математика. 2 , 88–92 (1952)
MathSciNet Статья МАТЕМАТИКА Google ученый
Вопрос собеседования по кодированию: Zero Matrix
public void zeroMatrix (boolean [] [] matrix) {
// Убедитесь, что входной массив не равен нулю
if (matrix.length == 0 || matrix [0 ] .length == 0) возврат;
// Определить, истинна ли первая строка или первый столбец
логическое rowZero = false, colZero = false;
для (логическое i: матрица [0]) {
rowZero | = i;
}
для (логическое [] i: матрица) {
colZero | = i [0];
}
// Для каждой ячейки не в первой строке / столбце, если это правда, установите для ячейки
// в первой строке / том же столбце и первом столбце / той же строке значение
/ / true
для (int i = 1; i for (int j = 1; j if (matrix [i] [j]) { matrix [i] [0] = true; матрица [0] [j] = истина; } } } // Пройдите по первому столбцу и установите для каждой строки значение true, где ячейка в // первый столбец истинно for (int i = 1; i if (matrix [i] [0]) { for (int j = 1; j matrix [i] [j] = true; } } } // Повторите для строк for (int j = 1; j if (matrix [0] [j ]) { for (int i = 1; i matrix [i] [j] = true; } } } // Установите для первой строки / столбца значение true, если необходимо if (rowZero) { for (int i = 0; i matrix [0] [i] = true; } } if (colZero) { for (int i = 0; i matrix [i] [0] = true; } } } Давайте поговорим об обнулении строк и столбцов в матрице при обнаружении 0 в сегодняшнем посте о взломе кода. Интервью 1 -8 Нулевая матрица. Всем привет! Надеюсь, у вас была хорошая неделя. Сегодня давайте перейдем прямо к этому и посмотрим на описание проблемы: Напишите алгоритм так, что если элемент является матрицей MxN, равной нулю, вся его> строка и столбец также будут обнулены. Хотя эта проблема выглядит обманчиво простой, есть несколько тонкостей, которые нам нужно продумать в рамках нашего подхода. Хорошо, давайте начнем с погружения в то, что алгоритм фактически просит нас сделать.Прежде всего нам нужно найти способ найти нули в матрице MxN. Это кажется достаточно простым. В худшем случае мы просто перебираем каждую строку, а затем также перебираем каждый индекс столбца для указанной строки. Итак, две петли. Легко! ✅ Затем во второй части задачи для каждого нуля, найденного в матрице, требуется «обнулить» соответствующую строку и столбец для указанного индекса, мы находим нуль. То, что не означает , заключается в том, что в термине каждый новый 0, который мы генерируем, также обнуляет его соответствующую строку и столбец.В противном случае мы всегда будем иметь нулевую матрицу всякий раз, когда хотя бы один ноль обнаруживается в матрице. 😱 Итак, в псевдокоде мы действительно ищем эту проблему при использовании итеративного подхода: Итак, почему мы должны сначала сгенерировать логическую матрицу и изменить ее, а не просто изменить непосредственно саму матрицу.Ну, например, у нас может быть , два нуля в одной строке. Даже если 1 ноль вызовет обнуление всей строки , мы все равно должны обнулить столбцы, соответствующие всем экземплярам нуля в исходной матрице . Таким образом, в случае использования картографа очень полезно сохранять здравомыслие во время итерации. Реализация этой проблемы неожиданно проста и разбита на несколько функций updateOriginalMatrixWithZeroes () выполняет итерацию по исходной матрице, сравнивая строку за строкой с нашей логической матрицей для каждого столбца, и в основном, если он находит истину, заменяет значение в точке в нашей исходной матрице нулевым значением. generateBooleanMatrix генерирует карту того, следует ли установить значение в исходной матрице равным нулю или оставить исходное значение. Это то, что изменяется, когда мы просматриваем матрицу, проверяющую нули. zeroOutRow () для данного номера строки заменит значение в каждом столбце данной строки на нулевое значение. Обратите внимание, что мы всегда начинаем с первого столбца (0-й индекс), потому что мы должны обнулить всю строку независимо от того, где находится ноль, если он был впервые обнаружен в строке. zeroOutColumn () для заданного номера строки заменит значение в каждой строке заданного столбца нулевым значением. Обратите внимание, что мы всегда начинаем с первой строки (0-й индекс), потому что мы должны обнулить весь столбец, независимо от того, где находится ноль, если он впервые обнаружен в столбце. Наша основная функция setZeroes () сначала проверяет, равна ли матрица 1x1 или меньше. В любом случае нет необходимости выполнять какую-либо работу, потому что нет дополнительных строк / столбцов для изменения.Так что мы просто выходим из функции. После этого мы инициализируем логическую матрицу размера MxN всеми ложными значениями. После завершения этой настройки мы начинаем итерацию, проверяя каждую запись матрицы на ноль. Если он найден, мы устанавливаем все соответствующие значения строки / столбца, в котором мы находим ноль, на , истинное значение . После того, как мы закончили итерацию по всей матрице, мы вызываем updateOriginalMatrixWithZeroes () , который будет использовать логическую матрицу для обновления значений в исходной матрице на месте до нуля в зависимости от того, истинно ли соответствующее значение в логической матрице. Как минимум наша сложность для этой задачи составляет O (MxN). Это потому, что в конце дня мы должны проверять каждую строку и столбец в матрице на поиск нулей. С точки зрения космической сложности мы проделали довольно плохую работу. Фактически мы создаем вторую матрицу MxN, которая действует как преобразователь. В сценариях с очень большой матрицей (или нехваткой системной памяти) это может занимать лишнее пространство. Так что может быть обходным путем? Оказывается, есть довольно умный способ избавиться от необходимости в полностью отдельной матрице слежения. Вспомните, если мы когда-нибудь найдем ноль, вся соответствующая строка и столбец для этого индекса должны быть обнулены. Это означает, что в определенный момент независимо от того, какие значения находятся в каждой строке / столбце в конце алгоритма, они будут уничтожены. Другими словами, что, если мы просто используем часть матрицы для хранения, где нужно обнулить остаток строки / столбца? Запутались? 🤔 Давайте сделаем небольшой пример. Допустим, у нас есть матрица 1 | 0 | 1 0 | 1 | 1 1 | 1 | 1 Что мы здесь интуитивно видим еще до того, как мы начнем писать код? Что ж ... независимо от остальных значений в строке 1, поскольку у нас уже есть ноль в первом столбце для этой строки, остальная часть столбца будет обнулена. Точно так же мы видим, что даже если индекс 0,0 равен единице, индекс 0,1 все равно обнулит его. Итак, ключ здесь - , почему бы нам просто не использовать первую строку / столбец матрицы для представления статуса обнуления, который нам нужно выполнить в конце? Итак, давайте посмотрим, как это может выглядеть в псевдокоде Теперь у меня нет реализации это (оставлю это вам, читателю, я могу продолжить с примером реализации позже). Но опять же, по сути, мы просто используем первую строку / столбец как своего рода ход / запрет для определения, обнулять ли все значения. Затем два особых случая (любые нули в начальном столбце или индекс 0,0 равен нулю) обрабатываются отдельно. Сложность необходимого износа не меняет O (MxN), потому что в конце дня нам все равно нужно перебирать все значения матрицы, чтобы определить, существуют ли нули. Однако наша космическая сложность теперь составляет звездный O (1), потому что мы используем существующую матрицу для определения статуса, и нам нужно только подключить 1 вспомогательную переменную, чтобы следить за нулевым статусом первого столбца. Спасибо как всегда и удачи, алгоритмы решения! https: // 2.bp.blogspot.com/-mo0yS1F3xtg/XkXGC5bjf1I/AAAAAAAACsU/ifq7sDBQRX8pQ5xWC6z1Y8jItT9C_a8TACLcBGAsYHQ/s1600/pruning.png Сжатие матрицы
Тензоры и матрицы являются строительными блоками моделей машинного обучения, в частности глубоких сетей. Часто необходимо иметь крошечные модели, чтобы их можно было разместить на таких устройствах, как телефоны, домашние помощники, авто, термостаты - это не только помогает смягчить проблемы доступности сети, задержки и энергопотребления, но также желательно для конечного использования ... Квантование : Другим популярным методом является квантование, при котором каждая запись или блок записей квантуются путем возможного округления записей до небольшого количества битов, так что каждая запись (или блок записей) заменяется квантованным кодом.Таким образом, исходная матрица раскладывается на кодовую книгу и закодированное представление; каждая запись в исходной матрице получается путем поиска кода в матрице кодирования в кодовой книге. Таким образом, его снова можно рассматривать как специальный продукт кодовой книги и матрицы кодирования. Кодовая книга может быть вычислена с помощью некоторого алгоритма кластеризации (например, k-средних) для записей или блоков записей матрицы. Фактически это частный случай изучения словаря с разреженным значением, поскольку каждый блок выражается как один из векторов в кодовой книге (который можно рассматривать как словарь) вместо разреженной комбинации.Сокращение также можно рассматривать как частный случай квантования, когда каждая запись или блок указывает на запись кодовой книги, которая либо равна нулю, либо сама по себе. Таким образом, существует континуум от сокращения до квантования и изучения словаря, и все они являются формами матричной факторизации, так же как и приближения с низким рангом. У нас есть открытый исходный код такого оператора сжатия, который может принимать любой пользовательский метод факторизации матрицы, указанный в определенном классе MatrixCompressor. Затем, чтобы применить определенный метод сжатия, просто вызывается apply_compression (M, compress = myCustomFactorization). Оператор динамически заменяет одну матрицу A произведением двух матриц B * C, которое получается путем факторизации A с помощью указанного пользовательского алгоритма факторизации.Оператор в режиме реального времени позволяет матрице A обучаться в течение некоторого времени и в определенный момент времени обучения применяет алгоритм факторизации и заменяет A факторами B * C, а затем продолжает обучение факторов (продукт '*' не обязательно должен быть стандартной матрицей умножение, но может быть любым настраиваемым методом, указанным в классе сжатия). Оператор сжатия может использовать любой из упомянутых выше методов факторизации. Для метода обучения по словарю у нас даже есть реализация обучения по словарю на основе OMP, которая быстрее, чем реализация scikit.У нас также есть улучшенный метод обрезки на основе градиента, который не только учитывает величину записей, чтобы решить, какие из них обрезать, но также его влияние на окончательные потери путем измерения градиента потерь по отношению к записи. Таким образом, мы выполняем мутацию сети в реальном времени, где вначале есть только одна матрица, а в конце это создает две матрицы в слое. Наши методы факторизации не обязательно должны быть основаны на градиенте, но могут включать в себя более дискретные алгоритмы стиля, такие как хеширование, OMP для изучения словаря или кластеризация для k-средних.Таким образом, наш оператор демонстрирует, что можно смешивать методы, основанные на непрерывном градиенте, с более традиционными дискретными алгоритмами. Эксперименты также включали метод, основанный на случайных проекциях, называемый simhash - матрица, подлежащая сжатию, умножается на матрицу случайных проекций, а элементы округляются до двоичных значений - таким образом, это факторизация в одну матрицу случайных проекций и двоичную матрицу. . На следующих графиках показано, как эти алгоритмы работают с моделями сжатия для CIFAR10 и PTB.Результаты показывают, что, хотя приближение с низким рангом превосходит симхаш и k-средние в CIFAR10, изучение словаря PTB немного лучше, чем приближение с низким рангом. Вычислить разложение LU с поворотом матрицы. Вычислить разложение LU с поворотом матрицы. Решите систему уравнений a x = b, учитывая LU-факторизацию Разложение по сингулярным значениям. Вычислить сингулярные значения матрицы. Построить сигма-матрицу в SVD из сингулярных значений и размера M, N. Постройте ортонормированный базис для диапазона A с помощью SVD Постройте ортонормированный базис для нулевого пространства A с помощью SVD Вычисляет факторизацию LDLt или Банча-Кауфмана симметричной / эрмитовой матрицы. Вычислить разложение Холецкого матрицы. Холецкий разлагает ленточную эрмитову положительно определенную матрицу Вычислить разложение Холецкого матрицы для использования в cho_solve Решите линейные уравнения A x = b, учитывая факторизацию Холецкого A. Решите линейные уравнения Вычислите полярное разложение. Вычислить QR-разложение матрицы. Рассчитайте разложение QR и умножьте Q на матрицу. Ранг-k Обновление QR Уменьшение числа QR при удалении строки или столбца Обновление QR при вставке строки или столбца Вычислить RQ-разложение матрицы. QZ-разложение для обобщенных собственных значений пары матриц. QZ-разложение для пары матриц с переупорядочением. Вычислить разложение Шура матрицы. Преобразование реальной формы Шура в сложную форму Шура. Вычислить форму матрицы Хессенберга. Преобразует комплексные собственные значения Взлом кода Интервью 1-8 Нулевая матрица (JavaScript)
Обсуждение нашего подхода
// генерируем «логическое» представление матрицы, для которой установлено значение false
// для каждой строки в матрице
// для каждого столбца в строке
// значение этого индекса равно нулю?
// если да, переворачиваем значения в логической матрице на истину для этой строки / столбца
// после завершения цикла вернуть модифицированную матрицу с новыми нулями в зависимости от результата логической матрицы
Реализация
const updateOriginalMatrixWithZeroes = (
booleanMatrix: boolean [] [],
матрица: число [] []
) => {
для (пусть i = 0; i Анализ сложности
Использование самой матрицы, чтобы указать, следует ли обнулить ее.
Анализ сложности
- Блог TensorFlow
Матрица сжатия
Тензоры и матрицы являются строительными блоками моделей машинного обучения, в частности глубоких сетей.Часто необходимо иметь крошечные модели, чтобы они могли поместиться на таких устройствах, как телефоны, домашние помощники, авто, термостаты - это не только помогает смягчить проблемы доступности сети, задержки и энергопотребления, но также желательно для конечных пользователей в качестве пользователя. данные для вывода не должны покидать устройство, что дает более сильное ощущение конфиденциальности. Поскольку такие устройства имеют меньшую емкость хранилища, вычислительные ресурсы и мощность, для того, чтобы модели соответствовали друг другу, часто приходится срезать углы, например, ограничивать размер словаря или снижать качество.Для этого полезно иметь возможность сжимать матрицы в разных слоях модели. Существует несколько популярных методов сжатия матриц, таких как отсечение, аппроксимация низкого ранга, квантование и случайное проецирование. Мы будем утверждать, что большинство из этих методов можно рассматривать как факторизацию матрицы на два фактора с помощью некоторого типа алгоритма факторизации. Методы сжатия
Сокращение : Популярным подходом является отсечение, при котором матрица разрежается путем отбрасывания (обнуления) мелких элементов - очень часто большие части матрицы могут быть отсечены без ущерба для ее производительности.
Приближение низкого ранга: Другой распространенный подход - приближение низкого ранга, когда исходная матрица A разлагается на две более тонкие матрицы путем минимизации ошибки Фробениуса | A-UV T | F где U, V - матрицы низкого ранга (скажем, ранга k). Эта минимизация может быть оптимально решена с помощью SVD (разложение по сингулярным значениям).
Изучение словаря : Вариантом аппроксимации низкого ранга является разреженная факторизация, при которой факторы разрежены вместо того, чтобы быть тонкими (обратите внимание, что тонкая матрица может рассматриваться как частный случай разреженности, поскольку тонкая матрица также похожа на большую матрицу с нулевыми записями в отсутствующие столбцы).Популярной формой разреженной факторизации является изучение словаря; это полезно для встраивания таблиц, которые высокие и тонкие и, следовательно, уже имеют низкий ранг для начала - изучение словаря использует возможность того, что, даже если количество встраиваемых записей может быть большим, может быть меньший словарь базовых векторов, такой что каждый вектор внедрения представляет собой некоторую разреженную комбинацию нескольких из этих векторов словаря - таким образом, он разлагает матрицу внедрения на продукт меньшей таблицы словаря и разреженной матрицы, которая указывает, какие словарные статьи объединяются для каждой записи внедрения.
Обычно используемые случайные проекции, которые включают использование случайной матрицы проекций для проецирования входных данных в вектор меньшей размерности, а затем обучение более тонкой матрицы, являются просто частным случаем факторизации матрицы, когда один из факторов является случайным. Факторизация как мутация
Применение этих различных типов матричной факторизации можно рассматривать как изменение сетевой архитектуры путем объединения слоя в продукт из двух слоев.
Оператор сжатия матрицы Tensorflow
Учитывая большое разнообразие алгоритмов сжатия матриц, было бы удобно иметь простой оператор, который можно было бы применить к матрице тензорного потока для сжатия матрицы с использованием любого из этих алгоритмов во время обучения. Это экономит накладные расходы на первое обучение полной матрицы, применение алгоритма факторизации для создания факторов, а затем создание другой модели для возможного повторного обучения одного из факторов. Например, для сокращения после того, как матрица масок M была идентифицирована, может все еще потребоваться продолжить обучение немаскированных записей.Аналогичным образом при изучении словаря можно продолжить обучение матрице словаря. CIFAR10
PTB
Вывод
Мы разработали оператор, который может принимать любую функцию сжатия матрицы, заданную как факторизацию, и создавать API тензорного потока для динамического применения этого сжатия во время обучения к любой переменной тензорного потока. Мы продемонстрировали его использование с помощью нескольких различных алгоритмов факторизации, включая изучение словаря, и показали экспериментальные результаты на моделях для CIFAR10 и PTB.Это также демонстрирует, как можно динамически комбинировать дискретные процедуры (такие как факторизация разреженной матрицы и кластеризация k-средних) с непрерывными процессами, такими как градиентный спуск. Благодарности
Эта работа стала возможной благодаря участию нескольких людей, включая Синь Вана, Бадиха Гази, Кхоа Тринь, Ян Ян, Судешна Рой и Люсин Оганесян. Также спасибо Зое Свиткиной и Суйог Гупта за помощь. Линейная алгебра (scipy.linalg) - SciPy v1.6.1 Справочное руководство
lu (a [, permute_l, overwrite_a, check_finite]) lu_factor (a [, overwrite_a, check_finite]) lu_solve (lu_and_piv, b [, trans,…]) svd (a [, full_matrices, compute_uv,…]) svdval (a [, overwrite_a, check_finite]) diagsvd (s, M, N) orth (A [, rcond]) пустое_пространство (A [, секунды]) ldl (A [, нижний, эрмит, overwrite_a,…]) cholesky (a [, lower, overwrite_a, check_finite]) cholesky_banded (ab [, overwrite_ab, lower,…]) cho_factor (a [, lower, overwrite_a, check_finite]) cho_solve (c_and_lower, b [, overwrite_b,…]) cho_solve_banded (cb_and_lower, b [,…]) A x = b , учитывая факторизацию Холецкого полосчатого эрмитова A . полярный (a [, сторона]) qr (a [, overwrite_a, lwork, mode, pivoting,…]) qr_multiply (a, c [, режим, поворот,…]) qr_update (Q, R, u, v [, overwrite_qruv,…]) qr_delete (Q, R, k, int p = 1 [, который,…]) qr_insert (Q, R, u, k [, which, rcond,…]) rq (a [, overwrite_a, lwork, mode, check_finite]) qz (A, B [, вывод, lwork, sort, overwrite_a,…]) ordqz (A, B [, сортировка, вывод, overwrite_a,…]) schur (a [, output, lwork, overwrite_a, sort,…]) rsf2csf (T, Z [, check_finite]) hessenberg (a [, calc_q, overwrite_a,…]) cdf2rdf (ш, в) w и собственные векторы v в действительные собственные значения в блочно-диагональной форме wr и соответствующие действительные собственные векторы vr , так что.